

LakeHouse Data Catalog
L*vi Strauss & Co., 2021
Explore Levi's Lakehouse Data Catalog: A comprehensive, automated tool for detailed data management in retail operations. Developed in-house using open-source tools within just 6 months, this catalog replaces a costly external service, saving Levi's $1 million annually. Navigate effortlessly through data layers and regions with a Google-like search function, significantly enhancing data governance and operational efficiency, all at no cost.
Diagram
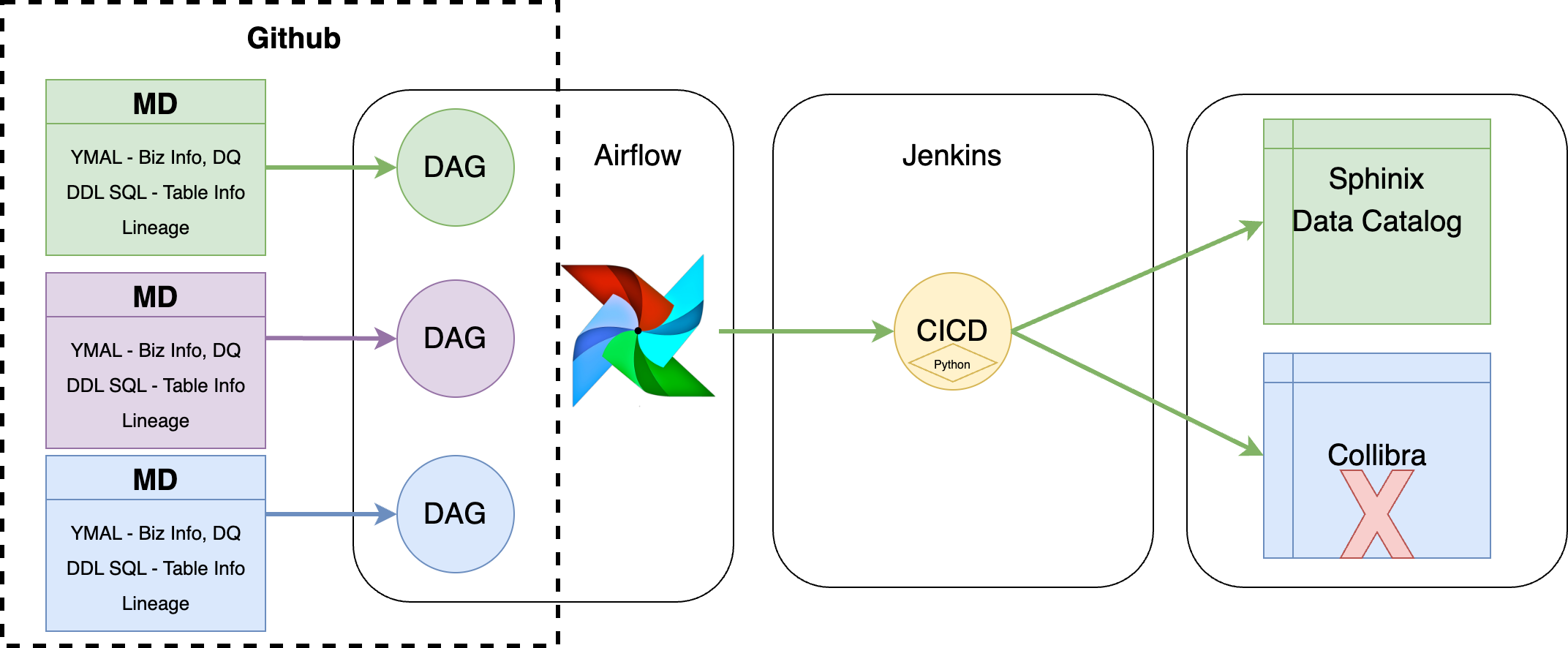
The diagram you provided illustrates the workflow for automatically collecting and deploying metadata into the Sphinx Data Catalog from various sources using a CI/CD pipeline. Here's a brief description of how the data catalog collects information:
1, Metadata Extraction from GitHub:
Metadata (MD) including DDL SQL (Data Definition Language for SQL databases), YAML files (defining business information and data quality checks), and data lineage information are maintained in a GitHub repository. This metadata is organized into different categories based on business areas like products, stores, inventory, and shipping.
2, CI/CD Pipeline Activation:
Jenkins, integrated with GitHub, triggers a CI/CD pipeline whenever changes are made to the metadata in the repository. This pipeline is configured to execute Python scripts that process the updated metadata.
3, Data Integration and Deployment:
The Python scripts handle the integration of metadata from different sources, including DBT (data build tool) for data transformation lineage and DBdiagram for database schema visualization. These scripts ensure that all metadata, including lineage generated from DBT and schema from DBdiagram, are accurately integrated.
4, Publishing to Sphinx Data Catalog:
Once the metadata is processed and integrated, the Python scripts automatically deploy it to the Sphinx Data Catalog. Sphinx, a documentation generator, converts the metadata into searchable HTML pages. This makes it accessible and searchable for users, similar to browsing a website.
5, End Result, Enhanced Accessibility:
The result is a fully automated system that ensures the Sphinx Data Catalog is always up-to-date with the latest metadata. Users can easily access and search through detailed documentation of data tables, schemas, and lineage directly from the Sphinx HTML pages.
This streamlined process enhances transparency, improves data governance, and enables efficient data management by providing a centralized, searchable catalog of comprehensive data metadata.
UI Details
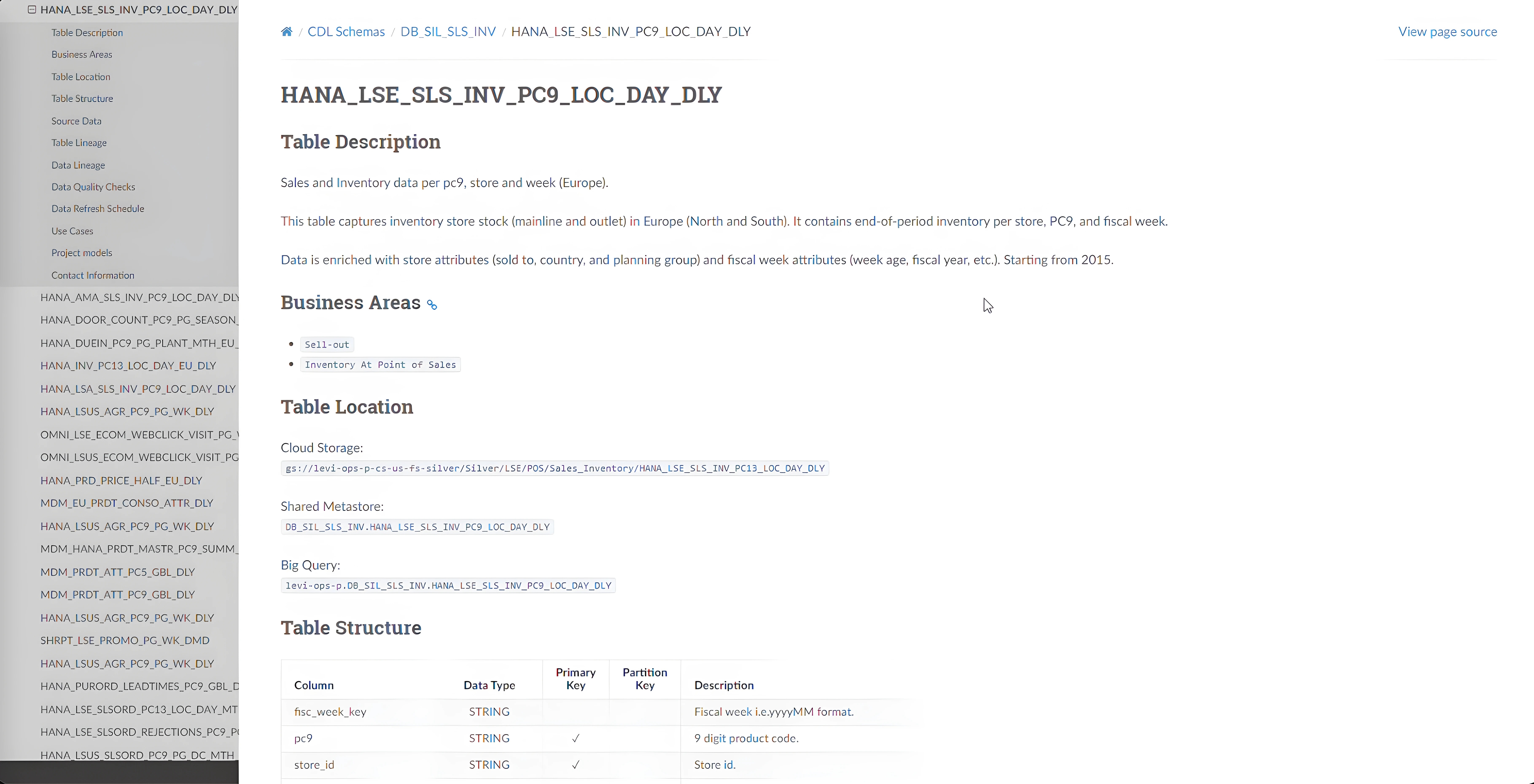
High-level table information
Tables in Lakehuse follows a naming convention as [Source_Data_Systems]-[Regions]-[Business_Areas]-[Table_Granularity_Details]-[Refresh_Frequency]. For example, this table includes a wealth of information such as a high-level description, business area labels or tags, its location within the Lakehouse, and a detailed table schema.
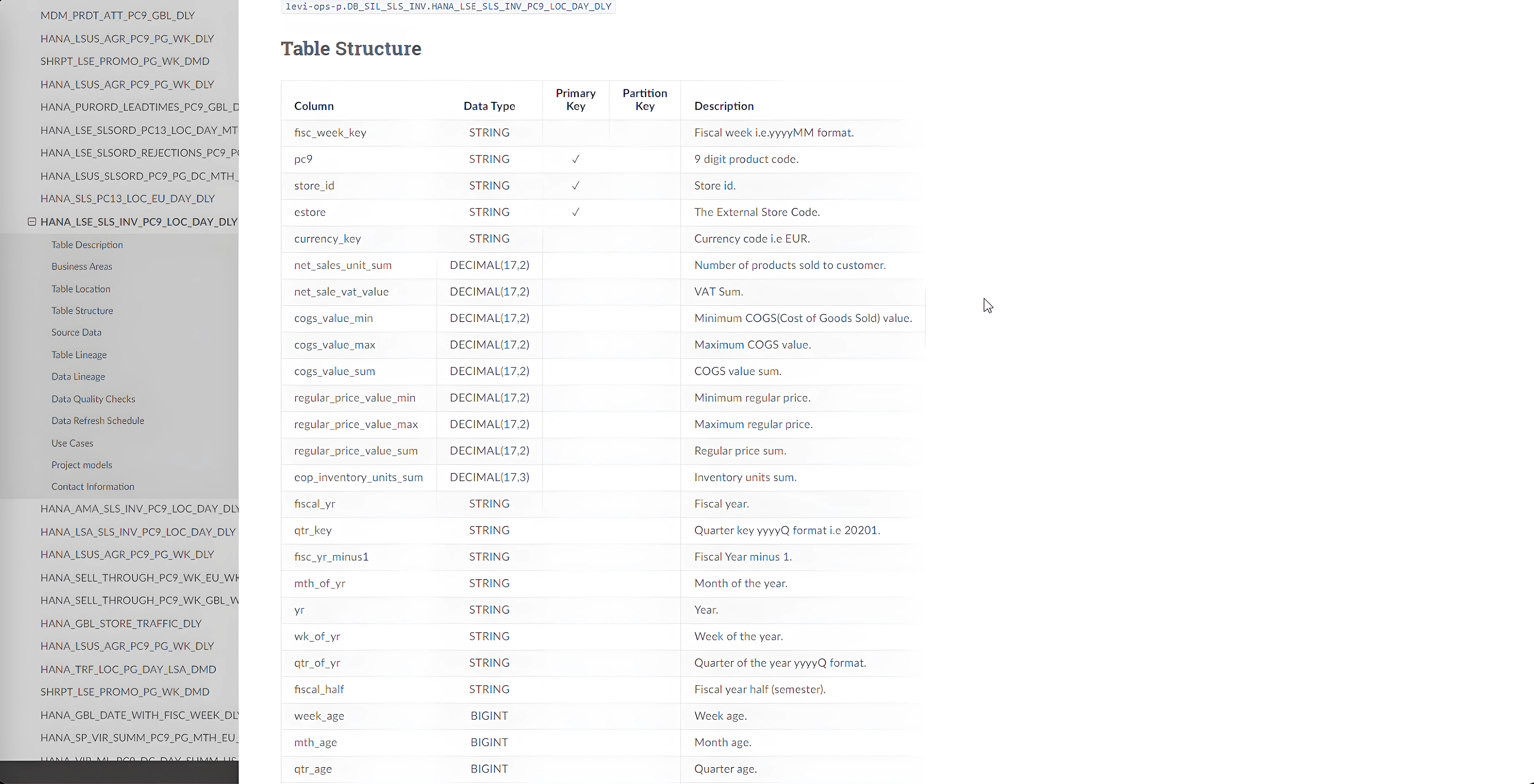
Table Schema Details
The detailed schema features column names, data types, primary keys, comprehensive column descriptions, and practical examples. It extends further with insights into source tables, data quality assessments, and refresh frequencies. A clear table schema enhances data integrity, simplifies system integration, and streamlines analysis and reporting. It ensures consistency across databases, aids in scalability, and fosters a unified understanding of data among stakeholders.
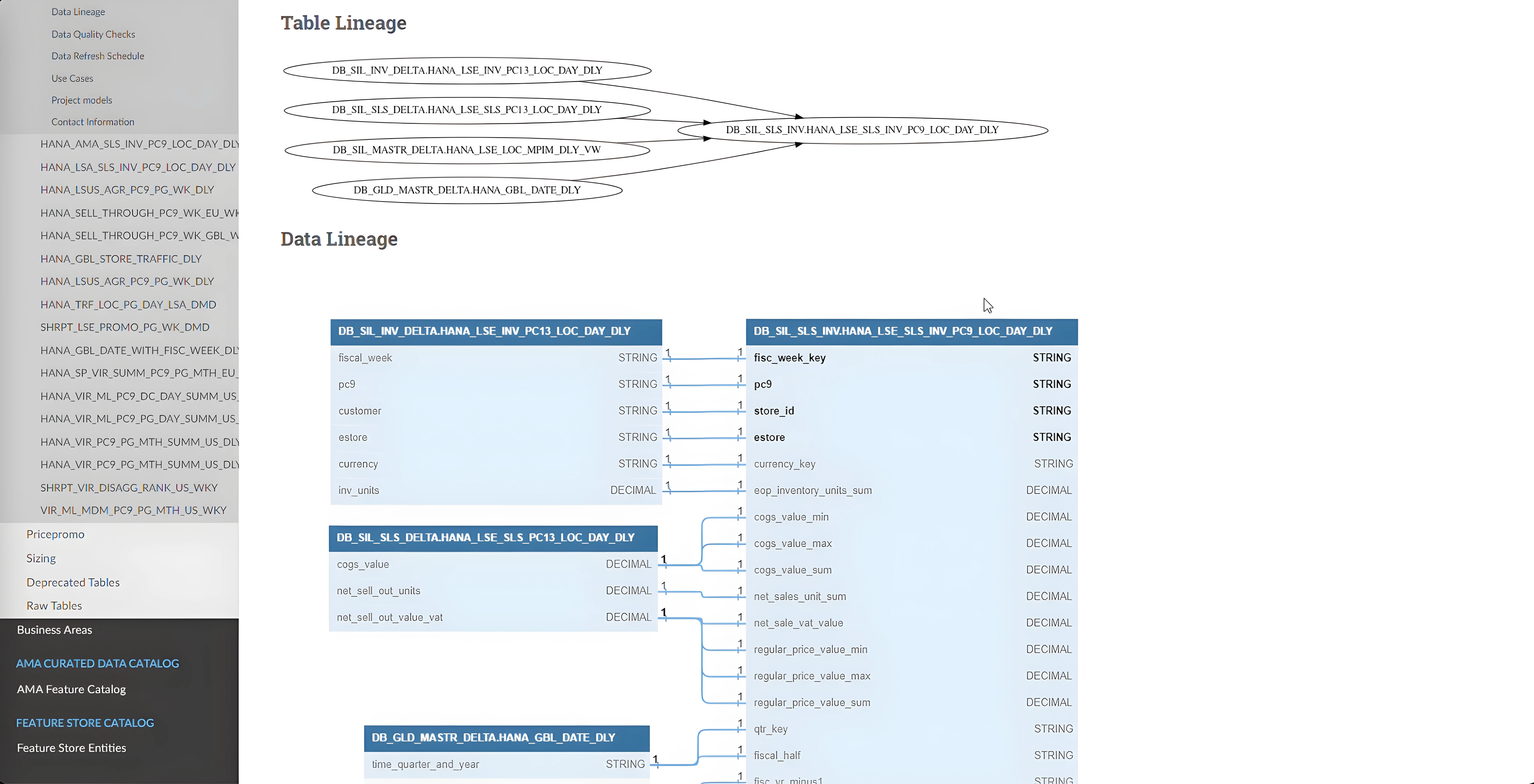
Data Lineage at Table and Column levels
Additionally, it provides insights into the data lineage at both the table and column levels. Understanding data lineage is crucial as it enhances transparency throughout the data lifecycle, enabling better data governance and compliance. Clear lineage facilitates easier tracking of data origin, transformation, and consumption, which is essential for troubleshooting and auditing purposes. It also aids in impact analysis, allowing teams to assess the potential effects of changes in data structures and pipelines, thereby minimizing risks associated with data-related modifications. Moreover, precise lineage information improves collaboration among various teams by providing a clear, understandable map of data flows and dependencies.
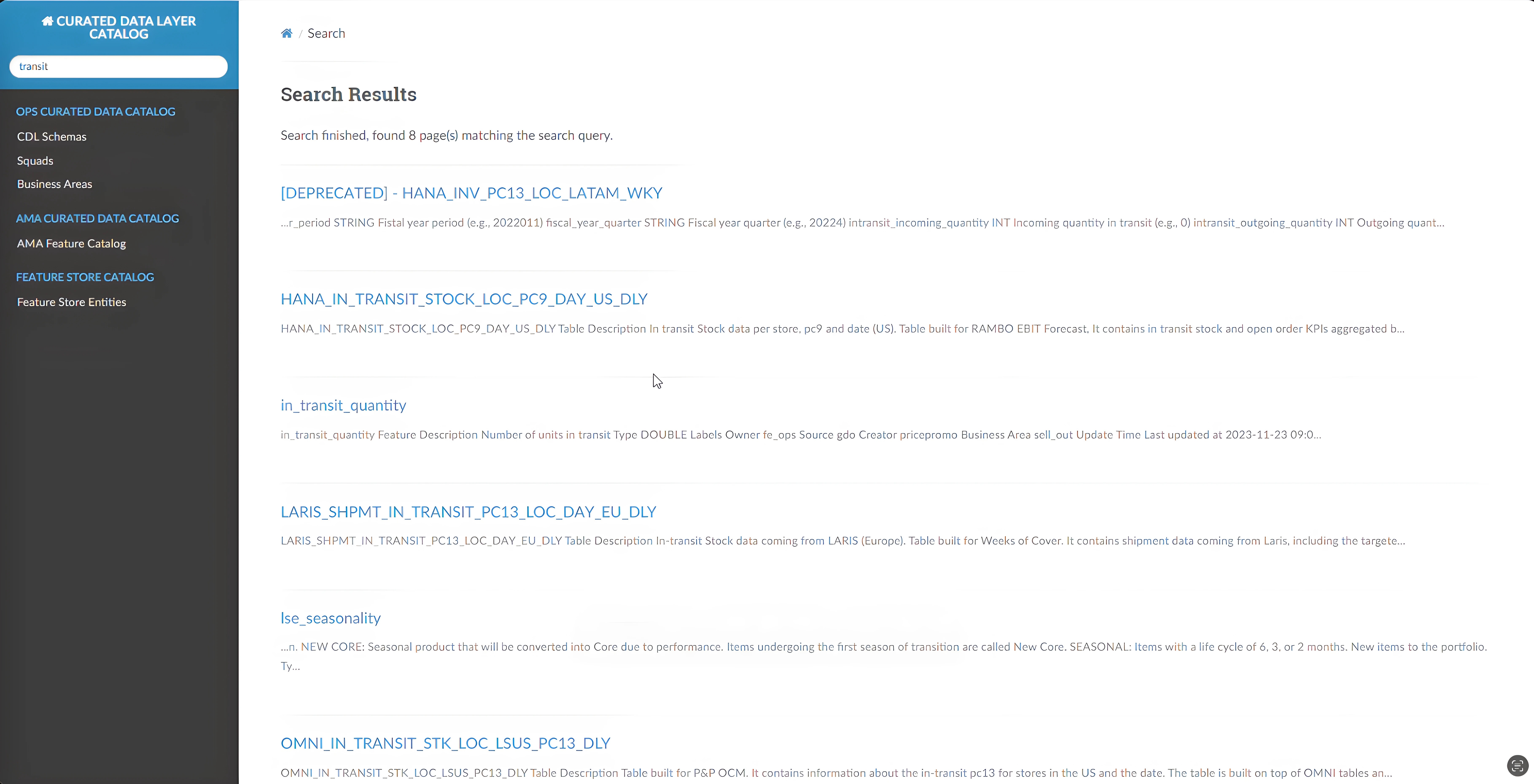
Catalog 'Google' search bar
The catalog's search bar operates with Google-like efficiency, enabling swift and precise data retrieval. By simply entering keywords such as "transit," users can instantly locate relevant tables of shipping information across any region. This feature is particularly beneficial for both seasoned employees and newcomers, enhancing data management and facilitating innovation. It ensures timely access to accurate data, empowering teams to make informed decisions and drive business success effectively.