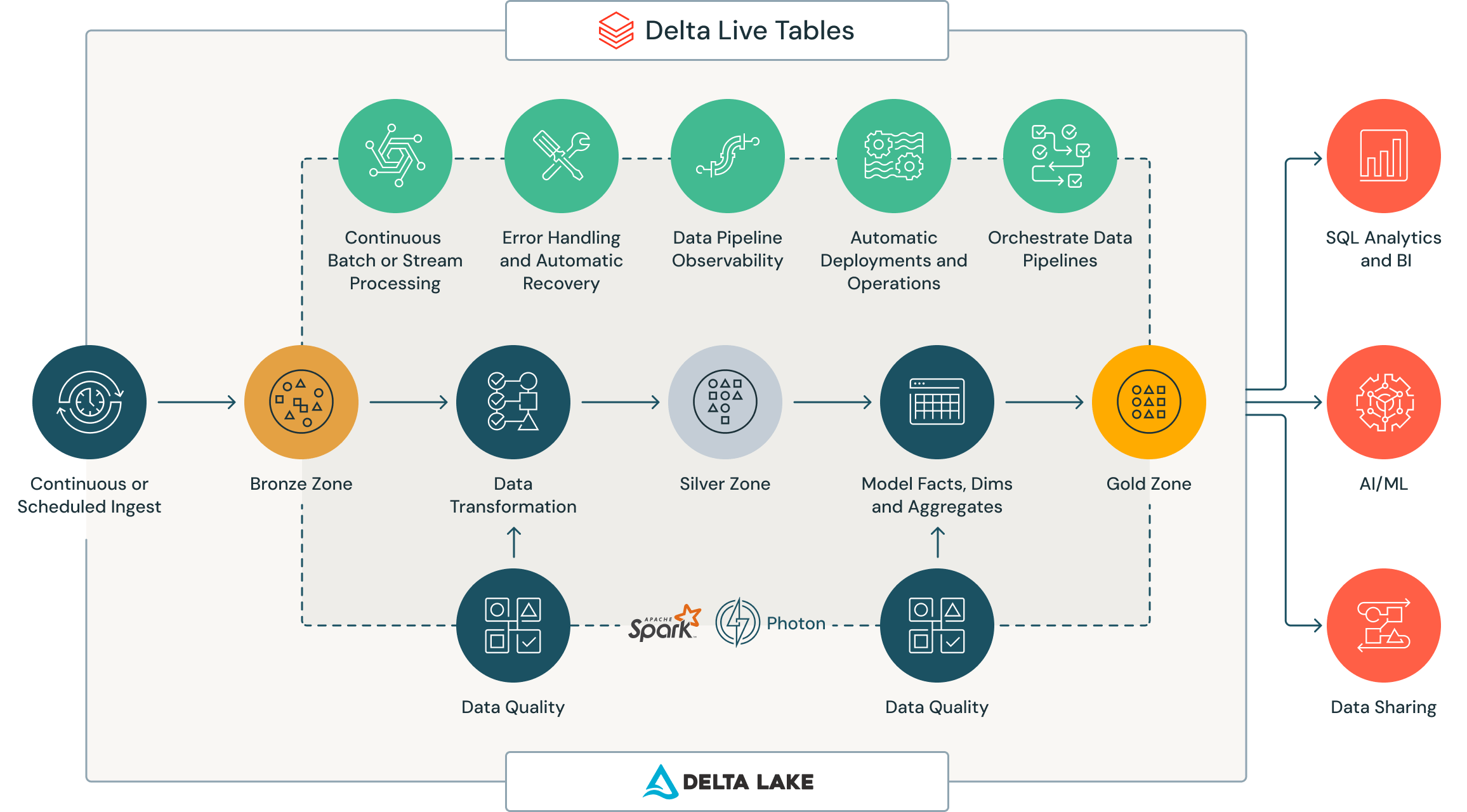
EUDL: Europe's Centralized Petabyte-Scale Data Lake
L*VIS, 2021

What: The project EUDL (Europe's Centralized PB-level Data Lake) aims to establish a unified data lake at Levi's, catering to the European sector.
Why: This initiative seeks to harness the potential of data to fuel Europe's digital landscape, enhancing decision-making, personalization, and operational efficiency.
How: By consolidating data into a centralized data lake, integrating data sources, and applying advanced analytics, Levi's will unlock the transformative power of data across the European operations, optimizing customer experiences and business outcomes.
Details
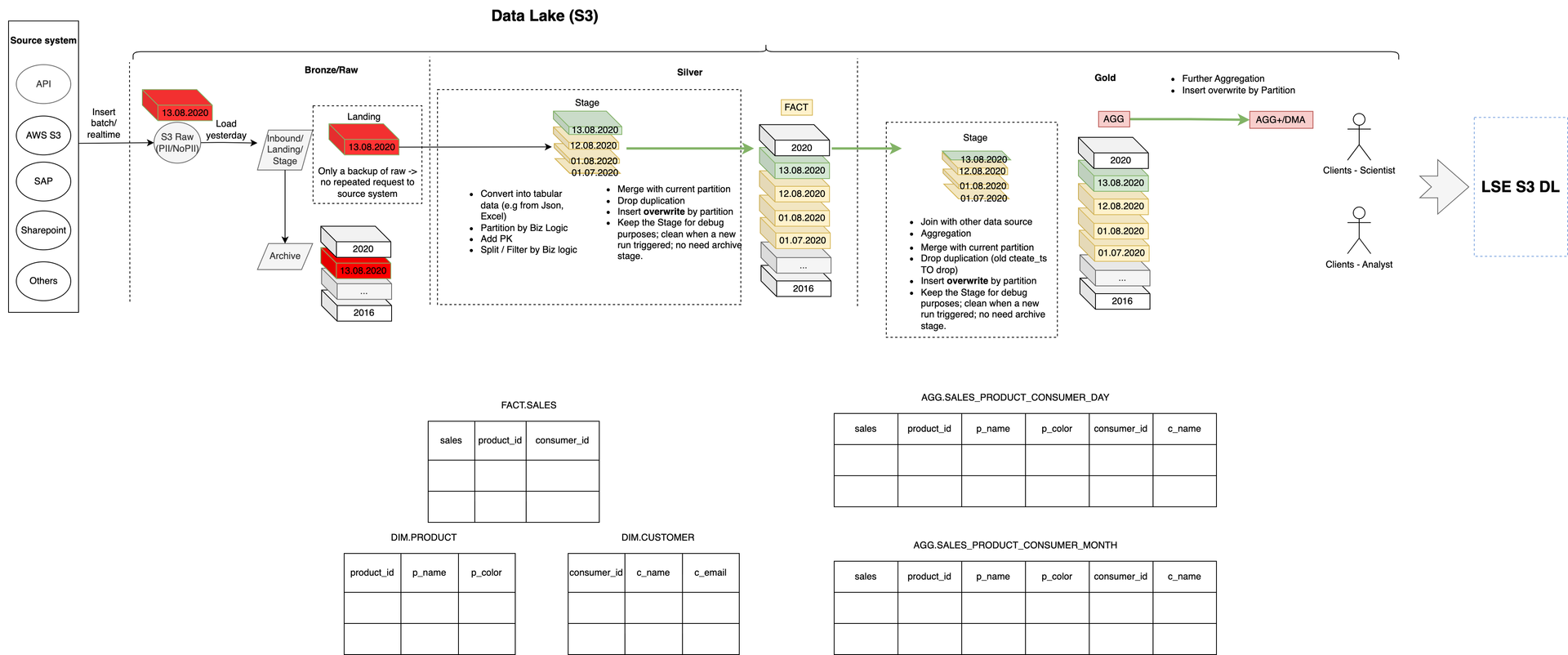
This diagram illustrates the data flow within L*vis ETL pipeline, e.g. on 13 August 2020, showcasing how data is processed through the Medallion Architecture — Bronze, Silver, and Gold layers. Despite some data delays from 12 August or earlier, the pipeline ensures that all data is processed effectively and integrated seamlessly into the ecosystem.
By employing the Medallion Architecture, L*vis data ecosystem demonstrates a reliable, scalable, and efficient process for managing both timely and delayed data, delivering high-quality outputs for business-critical decisions.
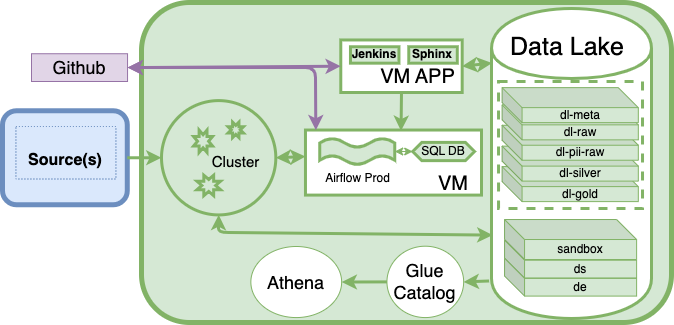
ETL Details in EUDL
Bronze Layer (Raw Data)
The Bronze layer serves as the foundation of L*vis data ecosystem, storing raw, unprocessed data from various sources such as APIs, AWS S3, SAP, and SharePoint. On 13 August 2020, the pipeline successfully ingested data from that day while also handling delays from earlier dates, such as 12 August 2020. This layer ensures that data is preserved in its original form, providing full traceability and acting as a backup to avoid repeated requests to source systems. By retaining raw data, the Bronze layer supports auditing and reprocessing, making it a robust starting point for the ETL pipeline.
Silver Layer (Cleaned and Refined Data)
In the Silver layer, raw data from the Bronze layer is transformed into structured and usable formats. The data is cleaned, deduplicated, and organized according to business logic, with primary keys (PKs) added for uniqueness. It is then partitioned and split into fact and dimension tables for better usability. For instance, fact tables like FACT.SALES contain sales transaction data, while dimension tables like DIM.PRODUCT and DIM.CUSTOMER provide descriptive details about products and customers. This layer provides reusable, high-quality datasets that can be leveraged across multiple business use cases, ensuring consistency and reducing redundancy.
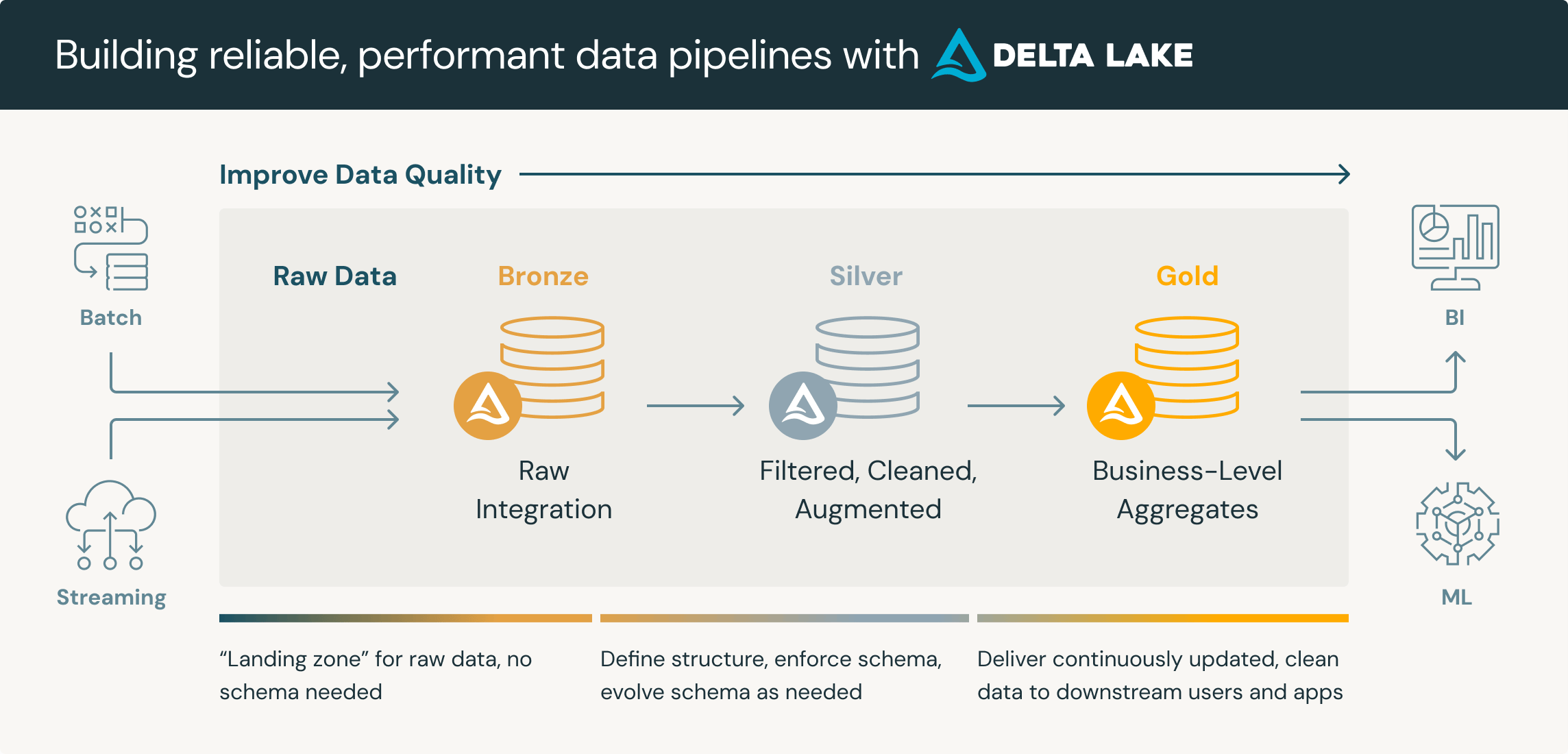
Gold Layer (Business-Ready Data)
The Gold layer produces highly curated, business-ready datasets tailored for analytics and decision-making. Data from the Silver layer is aggregated and joined with other sources to create enriched outputs, such as daily and monthly sales metrics. For example, the aggregated table AGG.SALES_PRODUCT_CONSUMER_DAY summarizes daily sales by product and customer, while AGG.SALES_PRODUCT_CONSUMER_MONTH provides monthly insights. Partitioning ensures efficient data retrieval, enabling analysts and machine learning models to access ready-to-use, performance-optimized datasets. The Gold layer is the endpoint for actionable insights, streamlining the decision-making process for critical business areas such as sales, inventory, and promotions.
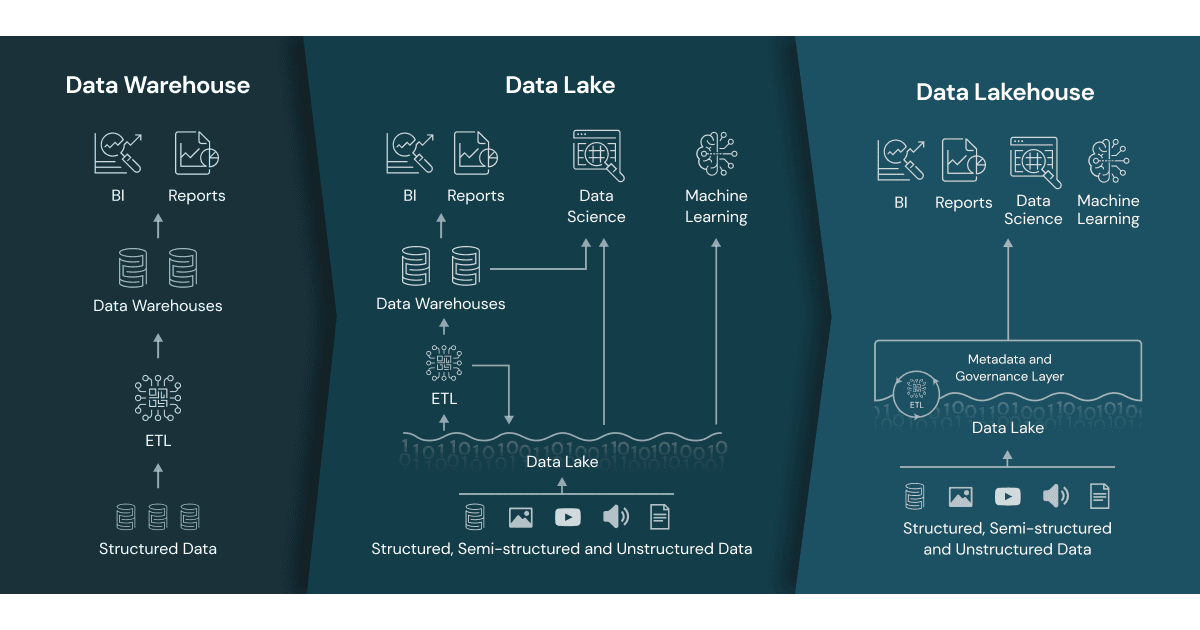
Key Insights & Business Benefits
This layered architecture highlights L*vis ability to handle data delays while maintaining data integrity and reliability. The pipeline ensures that even delayed data from earlier days is seamlessly processed, preserving business-critical information. Data lineage from the Bronze layer to the Gold layer is clear and traceable, supporting error troubleshooting and compliance. Additionally, the Gold layer's aggregated datasets optimize analytics workflows by reducing on-the-fly calculations, enabling faster decision-making. Overall, the Medallion Architecture provides scalability, reusability, and robustness, delivering high-quality data outputs that drive critical business decisions and improve operational efficiency.