
HDFS-K System
The Big Data HDFS Processing
Kpsule
HDFS, a primary distributed storage usingHadoop
, pre-filters the messy tracking data to the readable statistical data, parses the pre-filtered data by Hadoop and generates CSV for the Kpsule Dashboard.Research Details
Why HDFS?
Efficient.
Hadoop, including HDFS, is well suited for distributed storage and distributed processing using commodity hardware. This is exactly our case at Kpsule. Till now, we have got more than 1400 Kpsules. Each day, they produce large amount of tracking statistical data that will be analyzed by the Kpsule marketing team to know the Kpsule performances and to generate the statistical reports for our clients. If using the normal SQL database query, a statistical report with 20 tables and 100 statistical indexes might take us 20 minutes. Neither our clients nor we could wait for this.
Fault tolerant and scalable.
It’s normal to have some error stats if millions of tracking stats need to be processed each time. For example, some JavaScript or Flash function might be crashed when some clients are using very old version browsers. With the traditional database processing, when error appears, the following data process could be stopped. With a high risk , we would lose all the data. It could be a big trouble since the company charges the money with these statistics. However, HDFS is more tolerant than the traditional database and has indeed helped us significantly reduced the risk of the data lost during the daily data analysis work at Kpsule.
Extremely simple to expand.
Till now, we have built an alert system for supervising of the data process in real time and integrated it into the Slack2. Therefore, whenever there is anything wrong during the data process, we will be able to notice this immediately before it has been too late.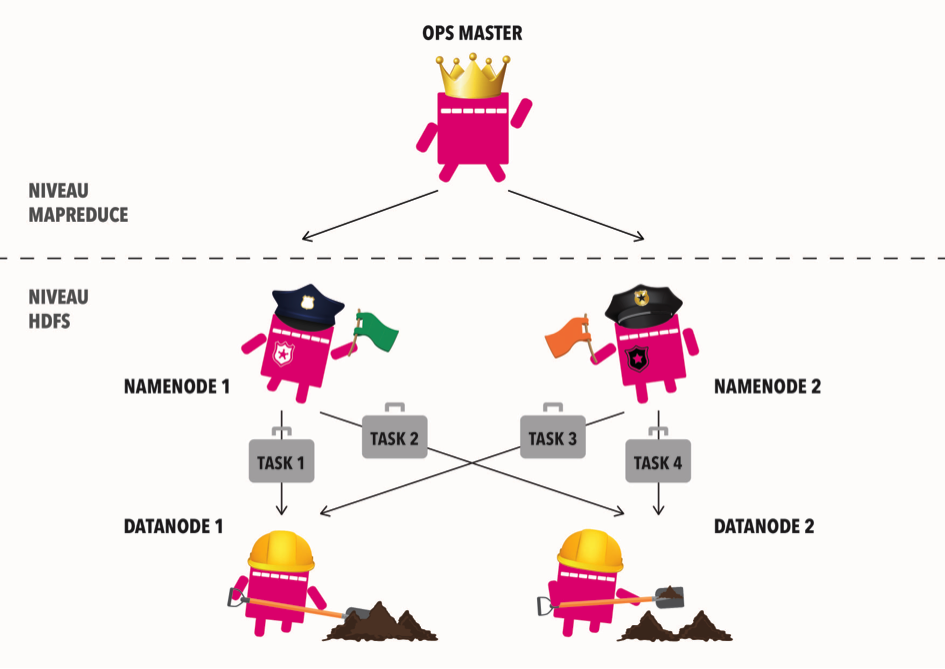
HDFS-K Structure
Kpsule HDFS Stats System has two NameNodes – NameNode 1 and NameNode 2, two DataNodes – DataNode 1 and DataNode 2 and one master client which is called OPS Master and in charge of coordinating the large set of Kpsule tracking data in real time with the help of the Amazon MapReduce1. The OPS Master contacts the NameNodes for file metadata or file modifications and perform actual file I/O directly with the DataNodes.
HDFS-K Process
This process will be done at 13:00 every day following three stages:
Pre-filter the messy tracking data to the readable statistical data.
Based on the Kpsule users’ behavior, the Flash version Kpsule or the JavaScript version Kpsule sends the tracking pixel information. This information may contain a lot of error messages as while. The Kpsule HDFS system only keeps the necessaries.
Parse and organize the pre-filtered data by Hadoop.
Only everything that we need will be processed by Hadoop and stored into MySQL database. From this point, the client has been able to receive the statistical report by email using the https://report.kpsule.me platform (Screenshot 1).
Generate CSV for the Kpsule Dashboard.
At the same time, a few CSV files for the past 7 days will be uploaded to the Amazon S3 each 2 hours every day. With the CSV files, the dashboard can charge the data and display the figures and charts based on the client’s’ need.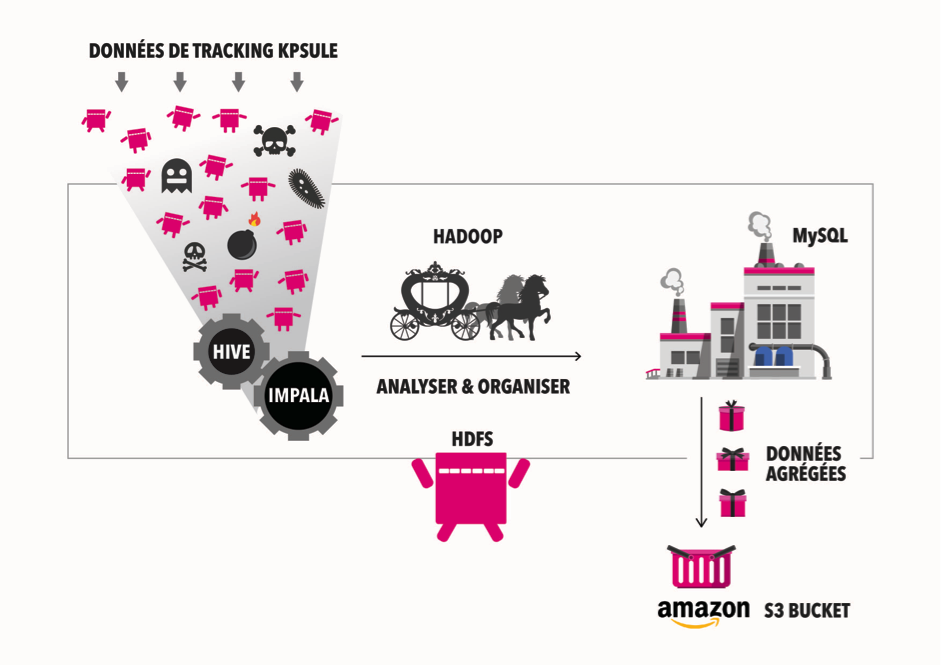
Development Cycle
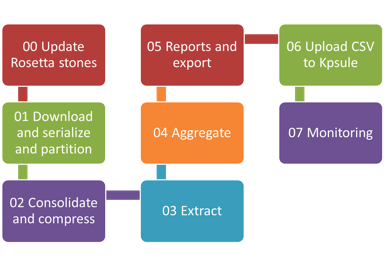
Version 1
Data Processing Workflow
Version 1
No UI for Version 1
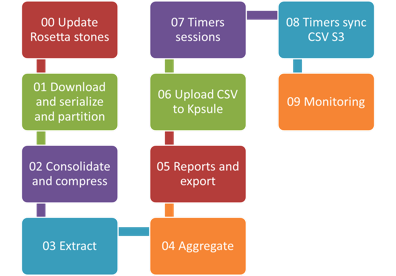
Version 2
Data Processing Workflow
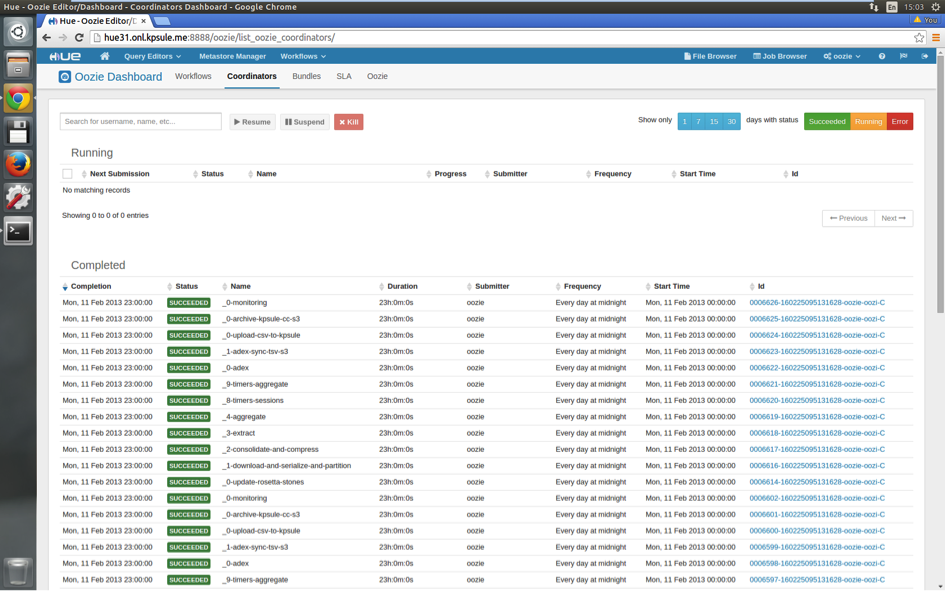
Version 2
UI on HUE