H&M Centralized Data Lake (HDL)
H&M Gr*up, 2020

This page outlines my experience as the sole Senior Data Engineer in the dynamic data engineering team at a top global fast fashion company in Sweden. It covers the setup of a centralized data lake with an architecture diagram, the formation and development of the team, and my leadership in data engineering practices.
Technical Architecture
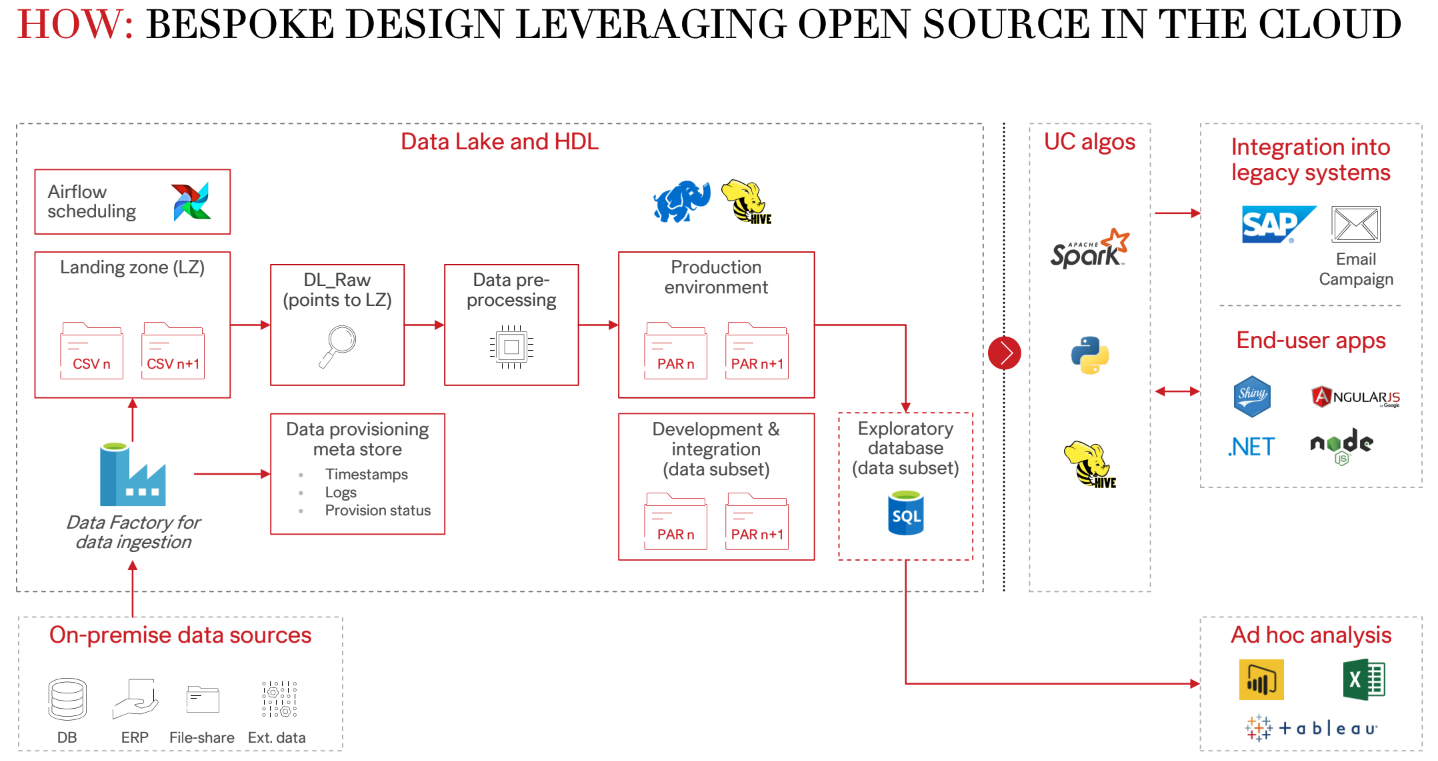
In the realm of business, the Centralized HM Data Lake (HDL) serves as a comprehensive repository, aggregating data from diverse sources spanning product design to customer experience within the fashion and retail sector. The primary objective of the HDL is to furnish enterprise-wide data access, offering a dependable, stable, and resilient singular point for data consumption. Notably, I led the construction and industrialization of over 200 pipelines during my tenure. This encompasses a wide spectrum of applications, including BI reporting, data analysis, and data science endeavors.
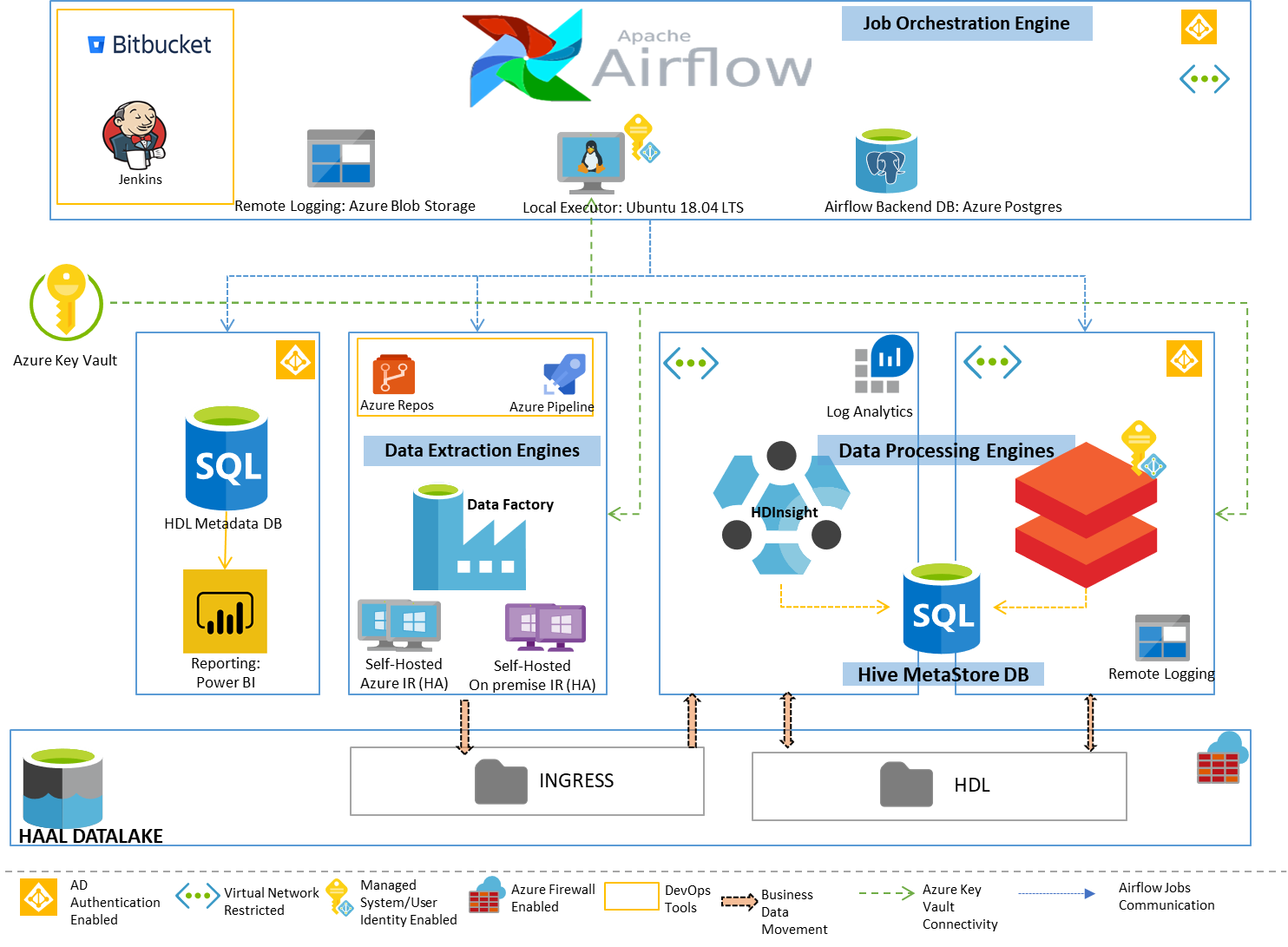
From a technical perspective, code in BitBucket undergoes Jenkins auto CICD for production deployment.
In the HDL ecosystem, the ETL process relies on Airflow, an open-source tool, for job scheduling in the Azure cloud. Raw data enters Azure Data Factory, progressing to a landing zone. Through an industrialized ETL process, Spark SQL enhances cloud-based computing. Resultant data is stored as parquet files in Cloud Storage.
Data processing encompasses two phases: INGRESS secures raw sources in a landing zone, while the HDL phase stores final datasets for client consumption.
For data exploration, Databricks serves as the primary notebook tool, facilitating computation in the initial phases.
Data Lake Diversity & Team
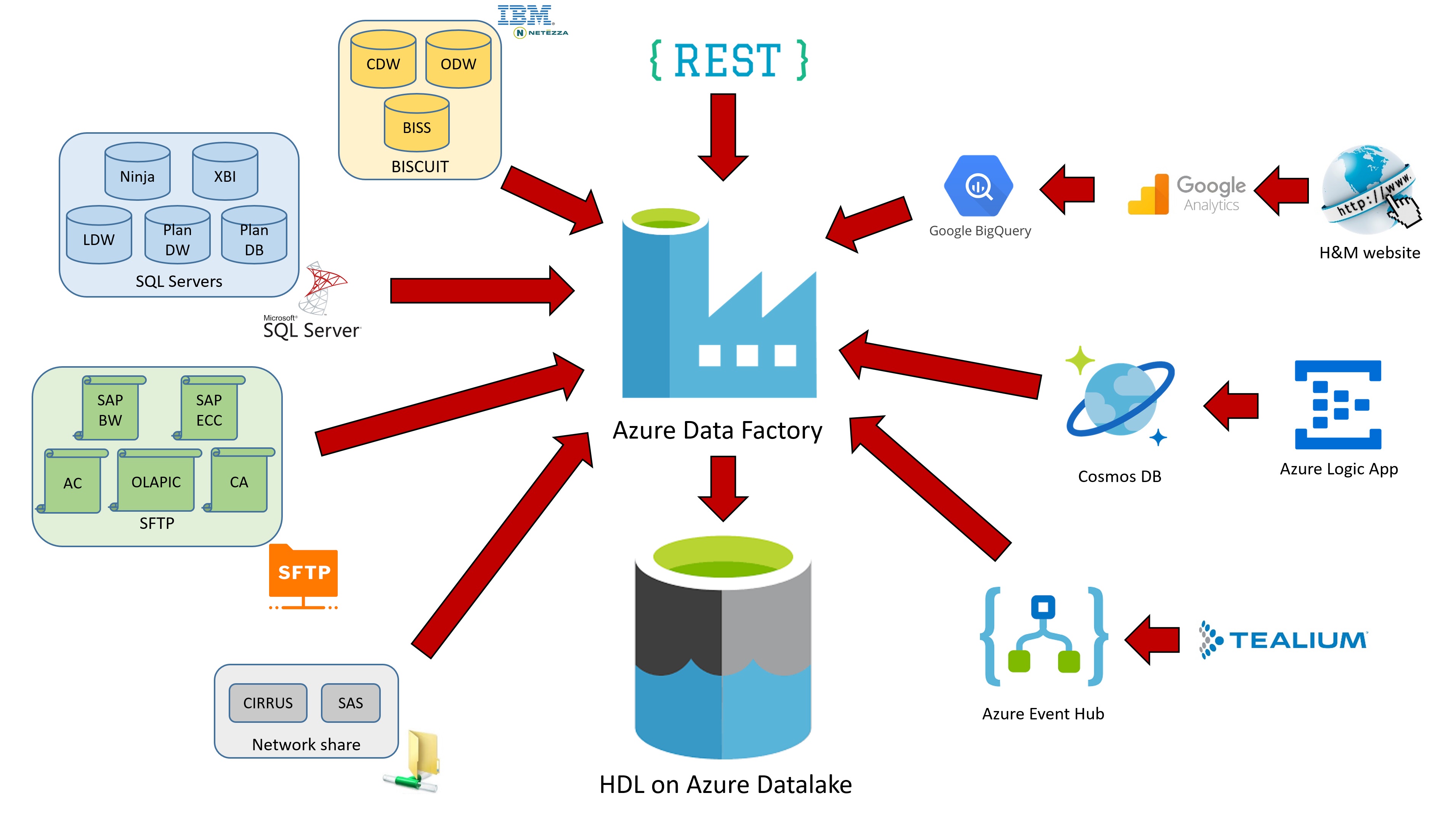
Diversity Data Sources
The remarkable aspect of HDL is its vast data source diversity. Technically, data originates from traditional warehouses, basic file systems like SFTP, online stats streaming (e.g., Google Analytics, Hybrids), and API requests. From a business standpoint, HDL provides an opportunity to engage with fashion industry datasets spanning product design to consumer experience.
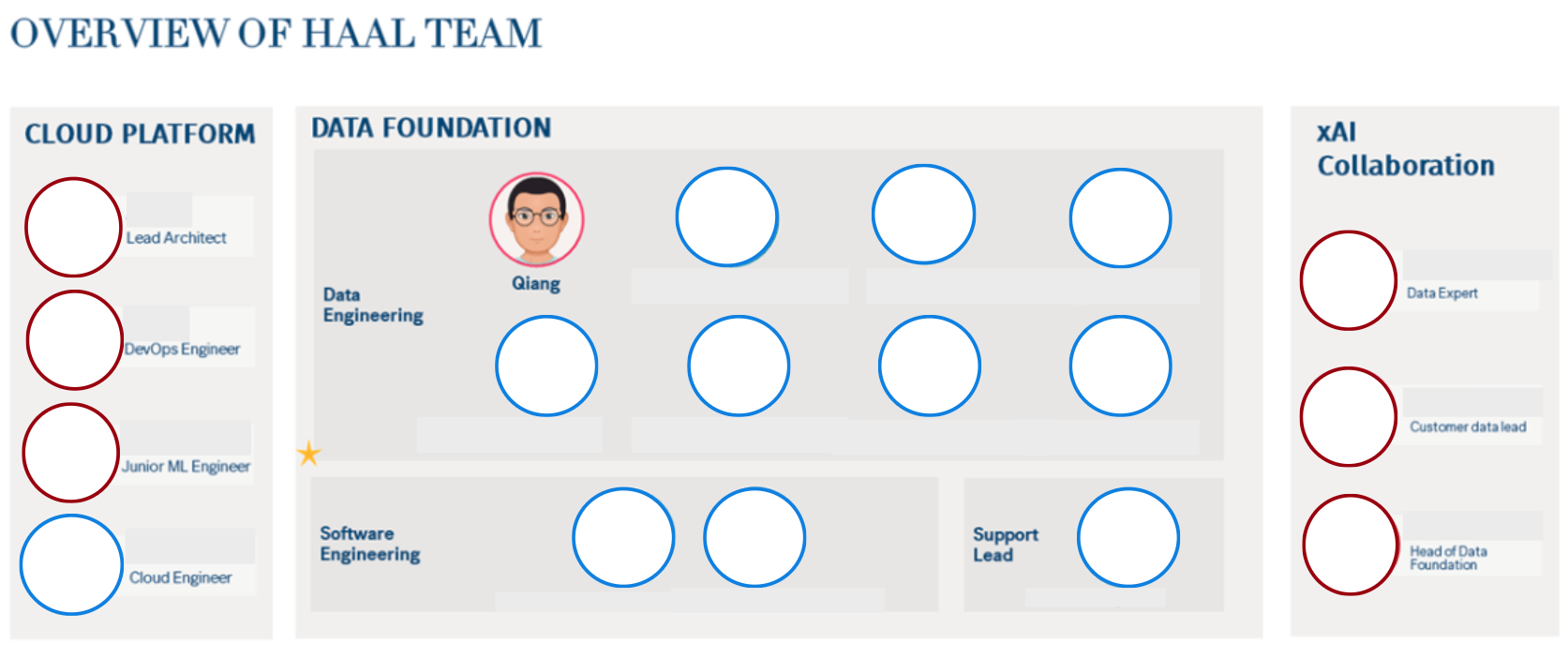
Data Team Structure
I joined as the first FTE senior data engineer amidst a team of 15+ data engineering consultants from diverse firms (e.g., BCG), along with DevOps, Data Specialists, and Product/Project Managers. Initially one of 30 FETs, HM Data and AI has since expanded to 150 in just 1.5 years, and reportedly over 500 by 2023. The rapid growth fostered a dynamic and enjoyable environment, uniting talents from 30+ nationalities into a cohesive, culturally diverse team.
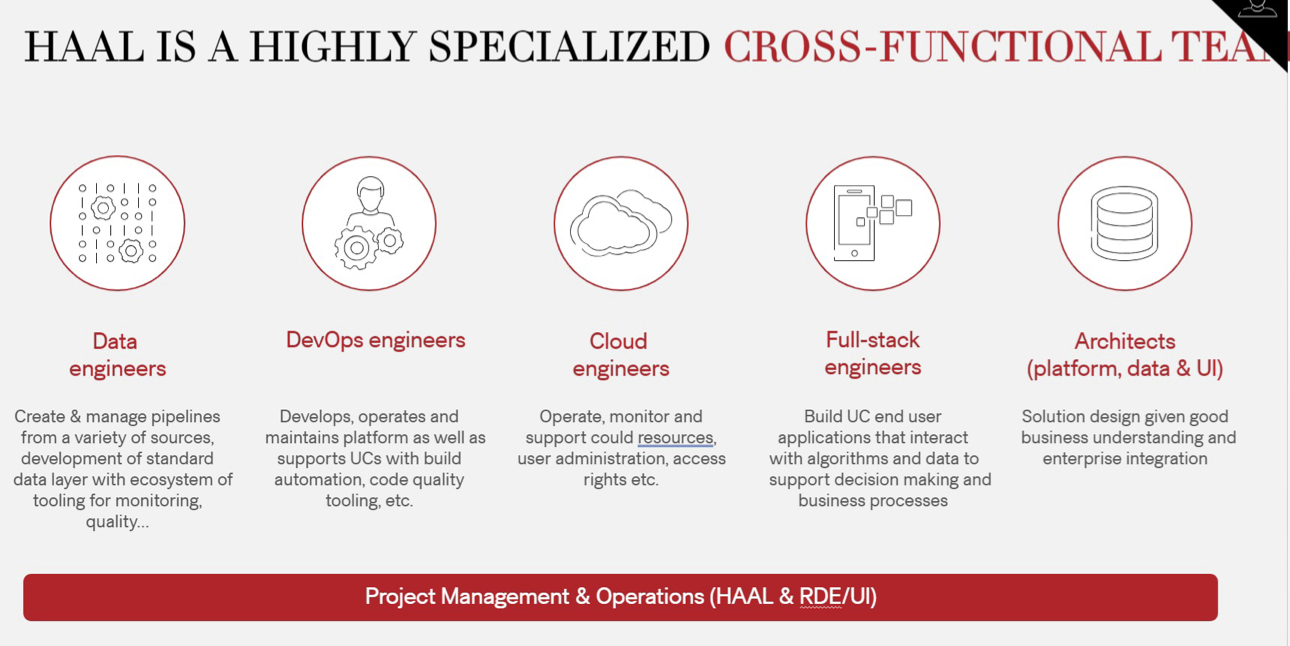
Data Team Roles and Responsibilities
Data Engineers: Responsible for pipeline creation, source management, and establishing standard data layers with monitoring and quality tools.
DevOps Engineers: Develop, operate, and maintain platforms, offering support with build automation, code quality tools, and more.
Cloud Engineers: Manage cloud resources, oversee user administration, access rights, and provide monitoring and support.
Architects (Platform, Data & UI): Design solutions with solid business insight and enterprise integration across platform, data, and user interface domains.
Full-stack Engineers: Construct end-user applications that interface with algorithms and data, facilitating decision-making and business processes.
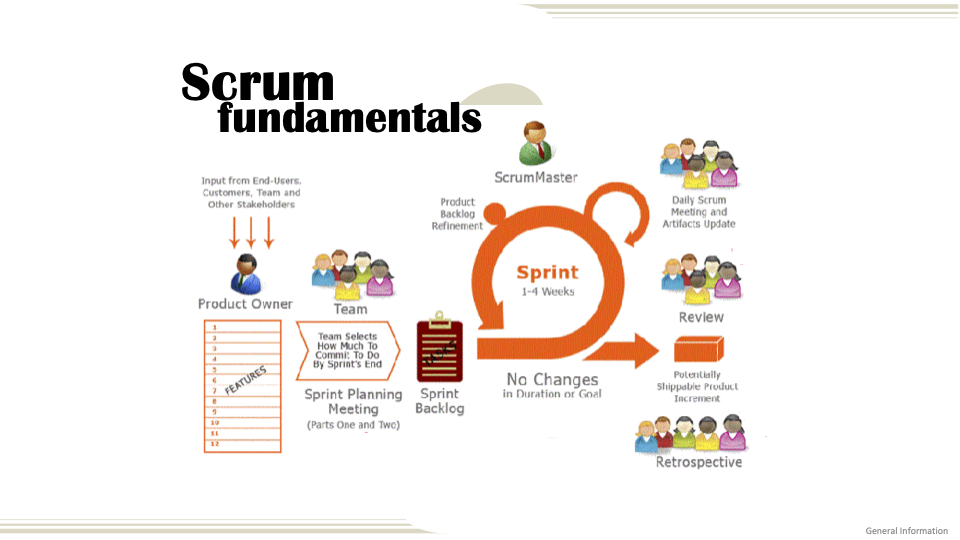
Agile Methodology
I gained trust and the opportunity to lead Agile projects, managing scrum for my engineering team at HM. This experience solidified my mastery and profound understanding of Agile's capacity to significantly enhance team engagement and productivity.