
IBM Mainframe (IBM Z) GCP Migration
N Br*wn (NBG), 2024
This project modernized
NBG’s legacy IBM Z Mainframe data warehouse
, replacing itsTeradata-based infrastructure
with ascalable, automated ETL pipeline on GCP
, fully funded by Google (£110K). The newprod-ready ETL pipeline
, completed in justone month
, extracts K90 data from IBM DB2, transfers it via SFTP, and ingests it into Cloud Storage using the GCP Mainframe Connector. Data is processed in Cloud Run, validated in BigQuery, and automated with Cloud Composer to ensure repeatability and scalability. This first-of-its-kind migration at NBG improved efficiency, enhanced data accessibility, and is projected to save£2M in Teradata licensing over two years
, while establishingstandardized naming conventions and best practices
to support future cloud transformations.Current Legacy Data Warehouse
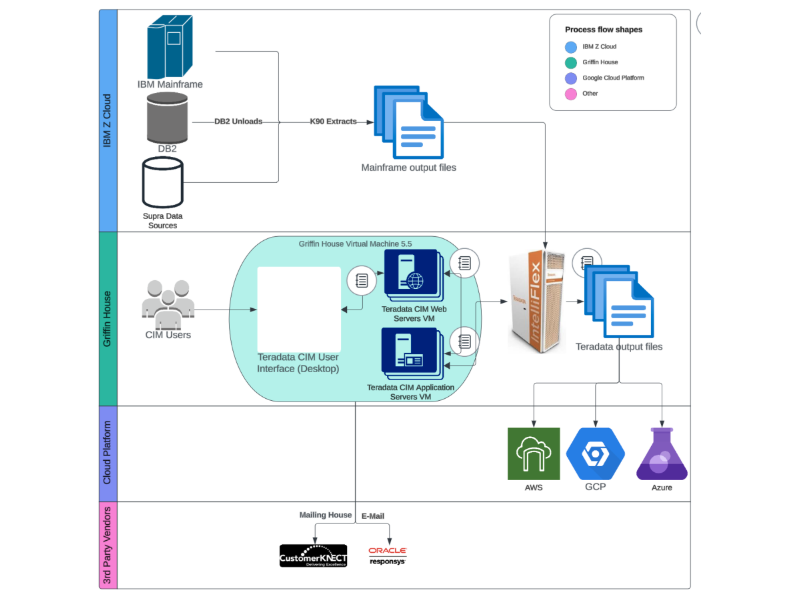
NBG Current Legacy Teradata Data Warehouse on IBM Z Mainframe
NBG integratesIBM Mainframe (IBM Z)
data with modern cloud infrastructure andTeradata CIM
for advanced data processing and customer engagement. K90 Extracts from IBM DB2 are securely processed within the IBM Z Cloud environment before being ingested into Teradata CIM, running on virtual machines at Griffin House (NBG HQ Office). Users interact with CIM via a desktop interface for analytics and customer management. Processed data is then distributed toAWS
,GCP
, andAzure
for further analytics or routed toMailing House
andOracle Responsys
for marketing campaigns. This hybrid cloud architecture enhances scalability, efficiency, and data-driven decision-making while optimizing legacy mainframe data for modern applications.Prod-Ready GCP Migration via Mainframe Connector
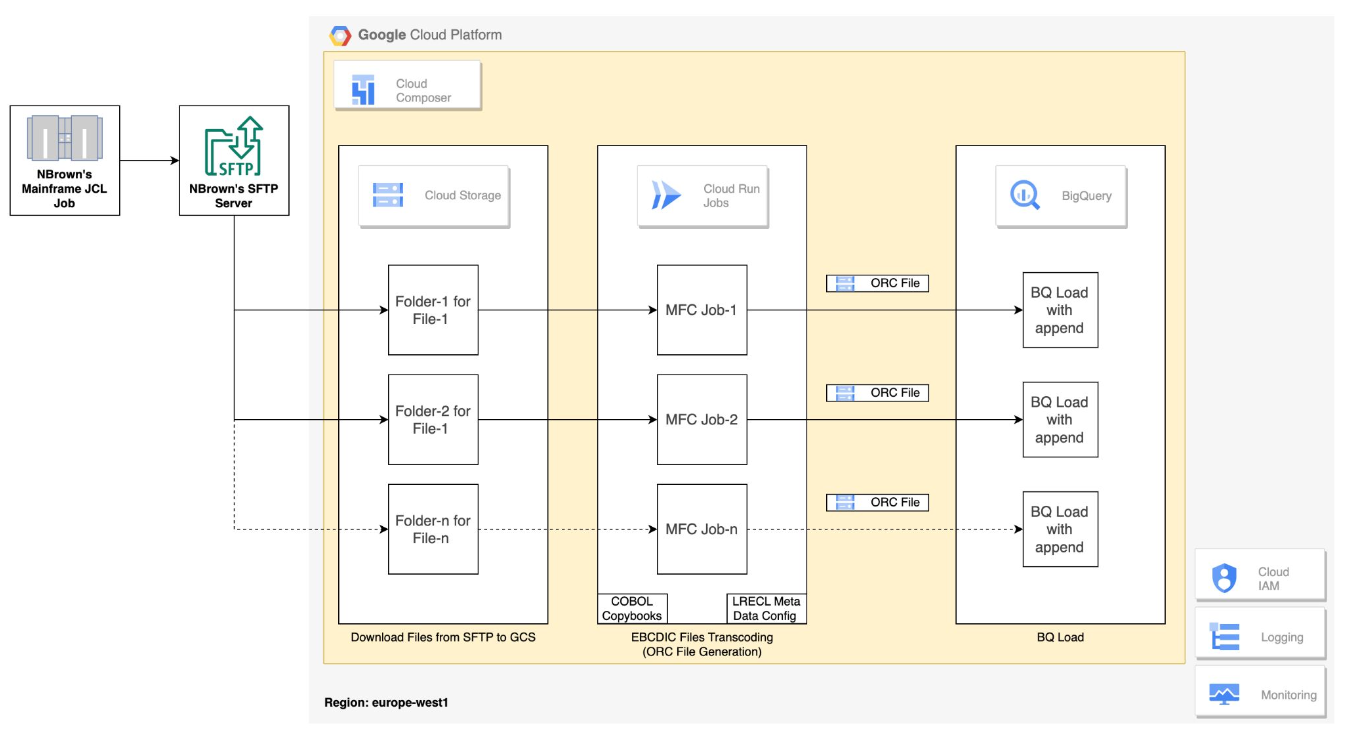
From Legacy to Prod-Ready GCP Migration: ETL Pipeline via Mainframe Connector
TheMainframe-to-GCP migration
leveragesInfrastructure as Code (IaC) with Terraform
to ensure scalability, security, and cost efficiency. By automating infrastructure provisioning, the solution modularizes components such asBigQuery, Cloud Run, and Dataplex
, enabling seamless integration with cloud services. The migration process starts withextracting mainframe data (K90 Extracts) from IBM DB2
, transferred viaSFTP
. Using theGCP Mainframe Connector
, data is loaded intoCloud Storage
, processed byCloud Run
, validated inBigQuery
, and structured using generated schemas. For automation,Cloud Composer
orchestrates pipeline execution. New files are onboarded by configuringenvironment variables
, updatingDAG templates
, and uploading necessary scripts. Thisscalable, repeatable architecture
modernizes legacy mainframe workloads, enhancing data accessibility and operational efficiency in GCP.