
Enterprise Data Science Feature Store (FS)
Harnessing Open-Source Solutions to Establish an Enterprise-Grade Feature Store at Almost Zero Cost
A Feature Store (FS) consolidates features, labels, and metadata in one repository. It serves for model training and prediction deployment. Features include metadata for traceability. Beneficial for project tracking and feature retrieval.
This page elaborates on the necessity of a Feature Store in data science projects, defines an optimal feature store, and outlines establishing an enterprise-grade feature store with open-source solutions at a minimal cost.
Why a Feature Store (FS)?
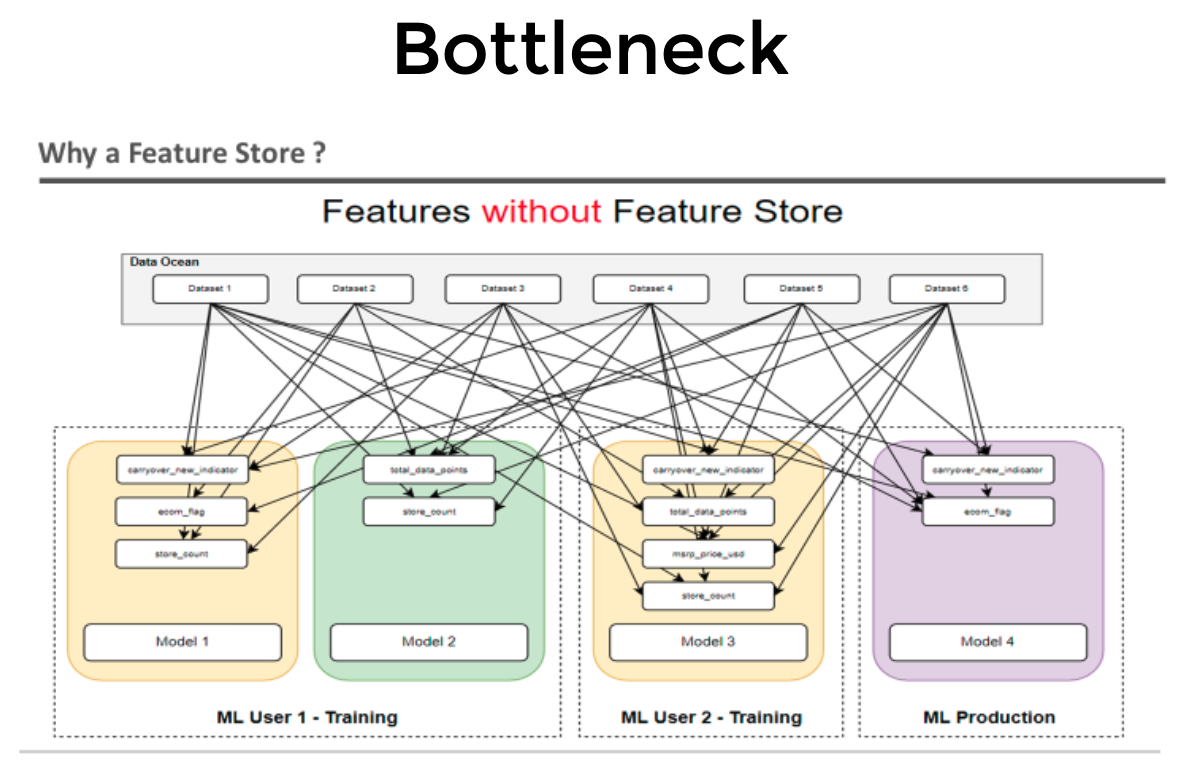
Bottleneck
Scalability: As the volume of data and complexity of models grow, managing features becomes increasingly challenging. A Feature Store offers scalability by handling large volumes of features and ensuring efficient data retrieval for training and inference.
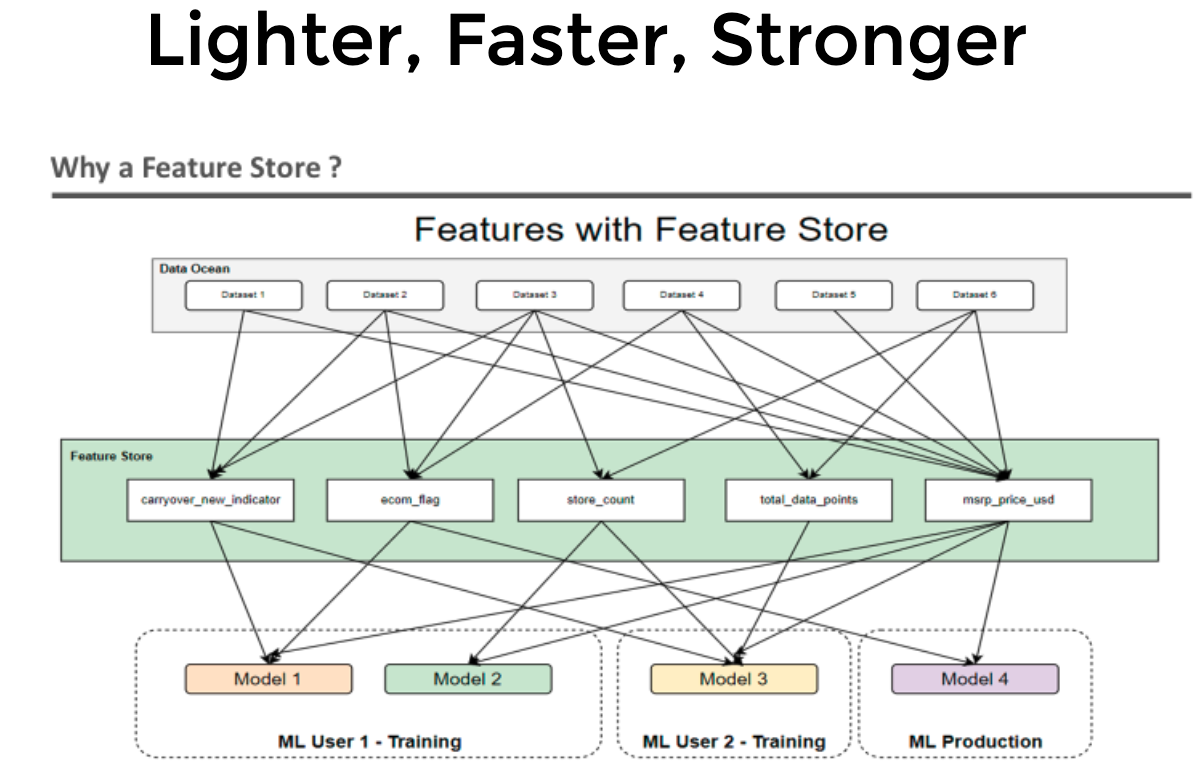
Lighter, Faster, Stronger
Reusability: A Feature Store allows data scientists to create, store, and share standardized features. These features can be reused across different projects, preventing redundant work and promoting consistency in feature engineering.
Model Performance: Standardized and well-curated features contribute to improved model performance. A Feature Store enables data scientists to experiment with different combinations of features and evaluate their impact on model accuracy and generalization.
Consistency: By maintaining a centralized repository of features, a Feature Store ensures that the same features are used consistently across various stages of model development, from training to deployment. This reduces the risk of introducing discrepancies and errors due to inconsistent feature engineering.
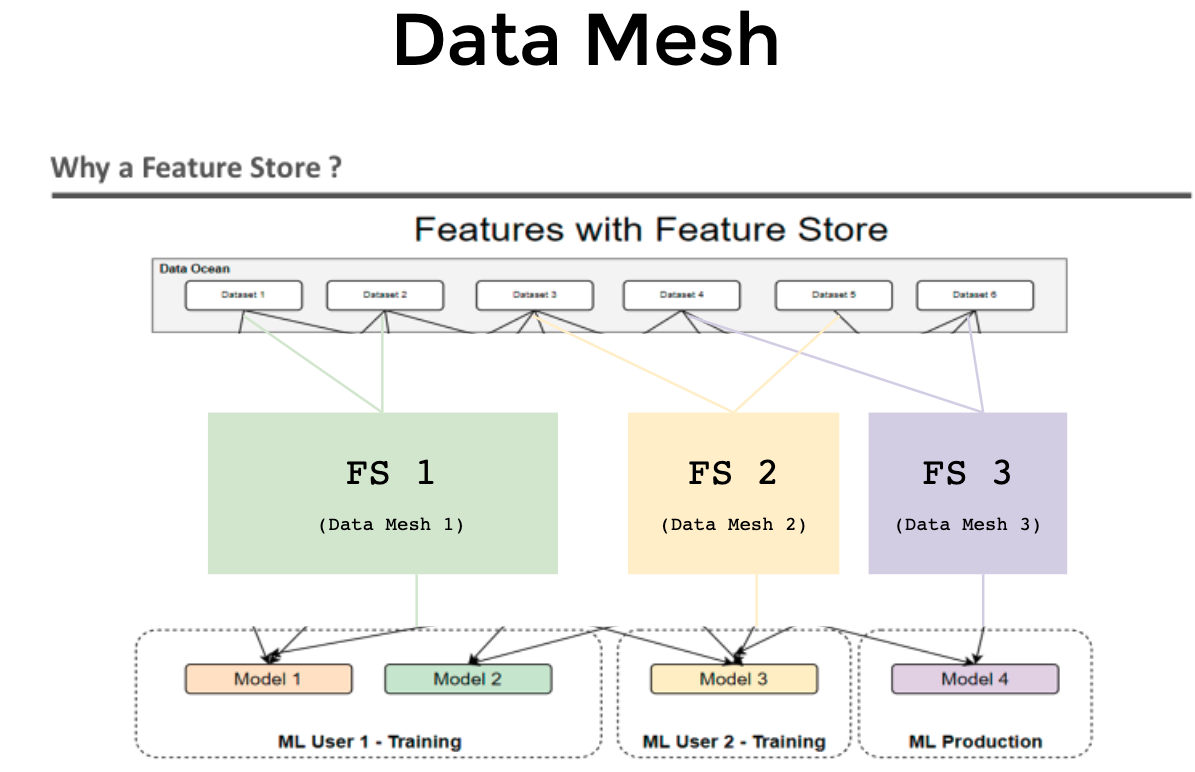
Data Mesh
Collaboration: Data Science teams often work on multiple projects simultaneously. A Feature Store promotes collaboration by allowing team members to share and access pre-defined features, reducing silos and fostering knowledge sharing.
An Ideal Feature Store (FS)
"Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data."
- Prof. Andrew Ng
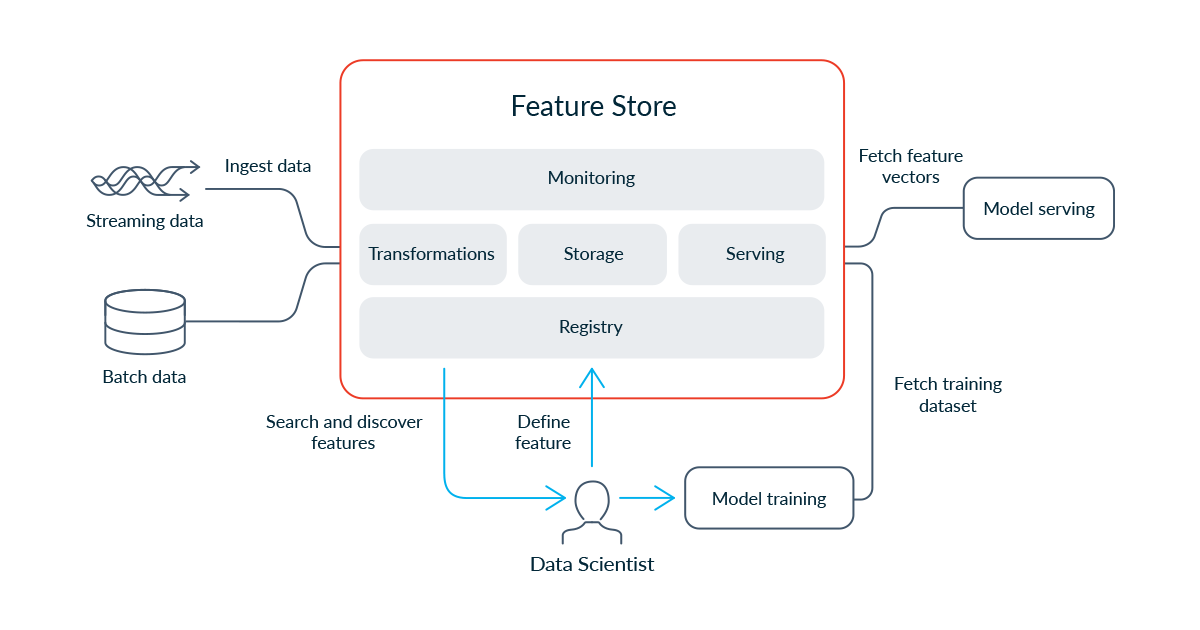
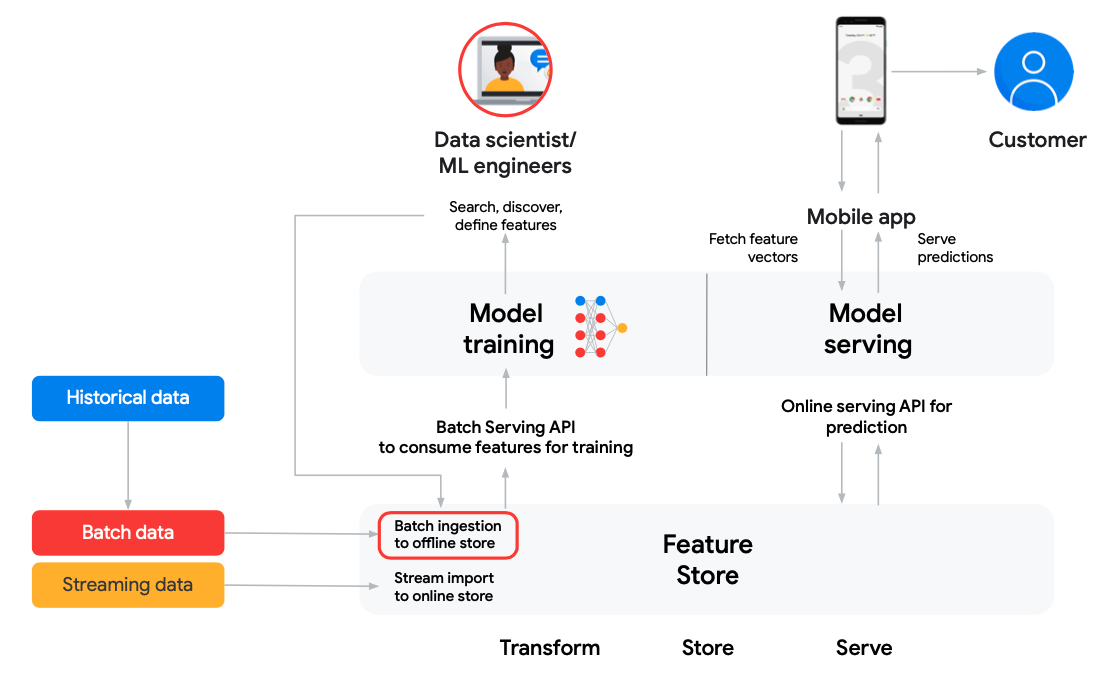
A Feature Store (FS) is a data storage facility that enables you to keep features, labels, and metadata together in one place. We can use a feature store for training models and serving predictions in the production environment. Each feature is stored along with metadata information. This is extremely helpful when working on a project, as every change can be tracked from start to finish, and each feature can be quickly recovered if needed.
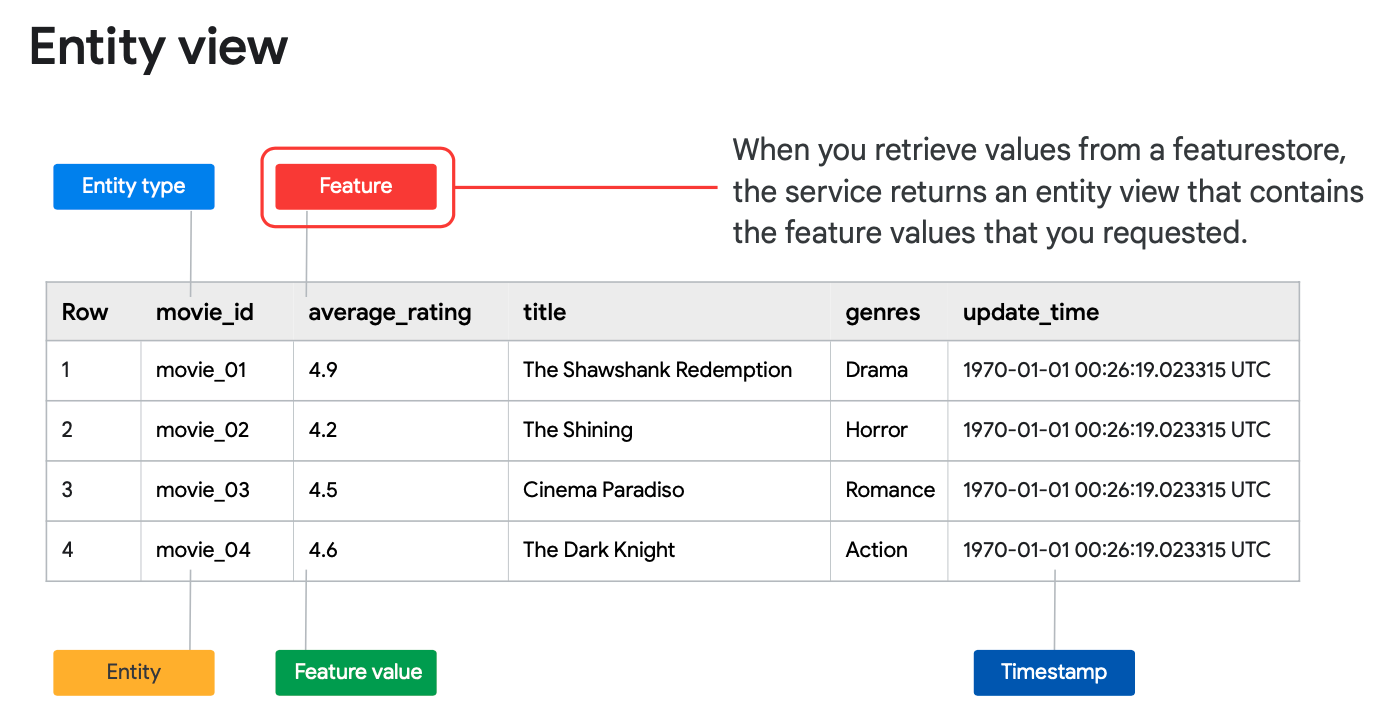
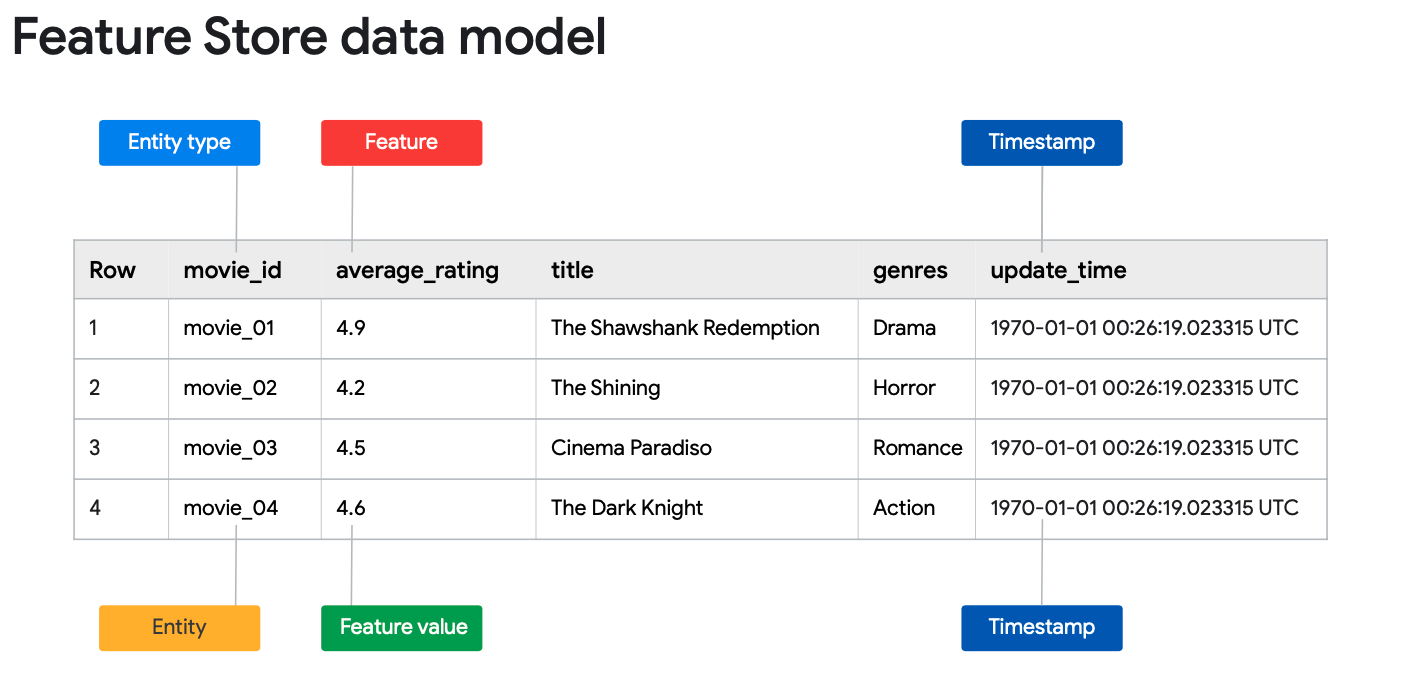
Feature vs Feature Value
Simply stated, a feature is a value that is passed as input to a model. Essentially, a feature describes some entity.
Feature Store captures feature values for a feature at a specific point in time. In other words, you can have multiple values for a given entity and feature.
Entity vs Entity Type
An entity type is a collection of semantically related features. You define your own entity types based on the concepts that are relevant to your use case. For example, a media budget might have the entity type budget that groups media budgets for newspapers, radio, and television.
An entity is an instance of an entity type. For example, budget_id and newspaper_budget are entities of the budget entity type. In a feature store, each entity must have a unique ID and must be of type STRING.
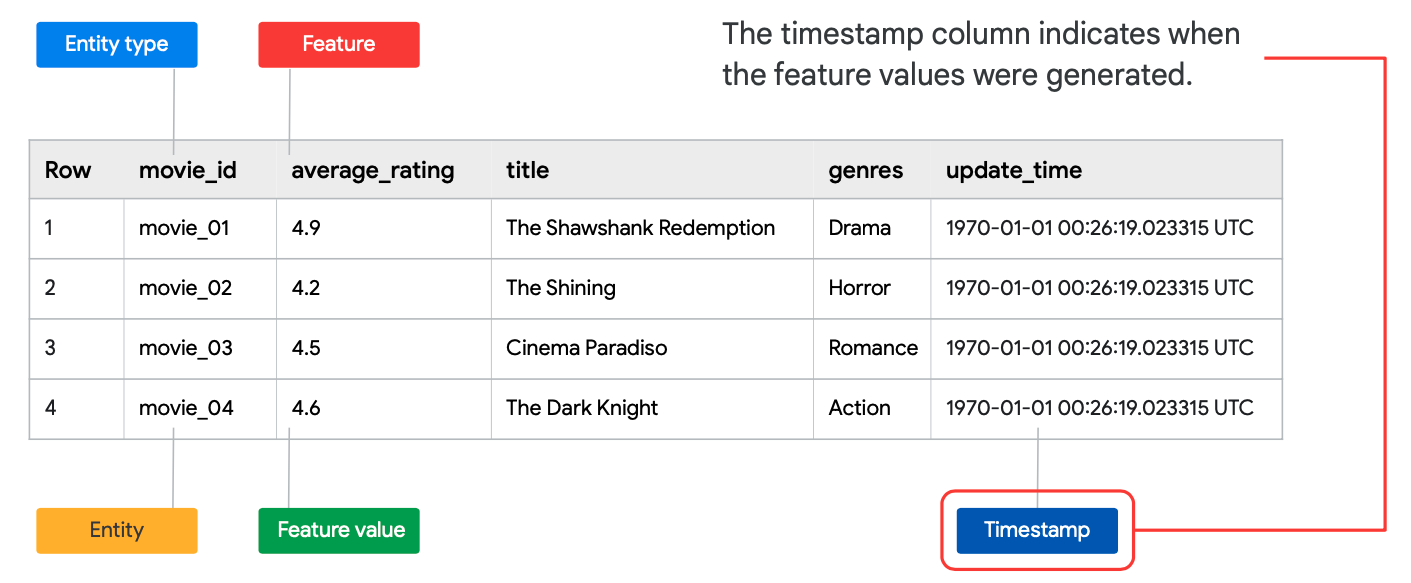
Feature Timestamp
The timestamp column indicates when the feature values were generated. In the feature store, the timestamps are an attribute of the feature values, not a separate resource type. If all feature values were generated at the same time, you are not required to have a timestamp column. You can specify the timestamp as part of your ingestion request.
Build your Open-Source Feature Store (FS) for Free
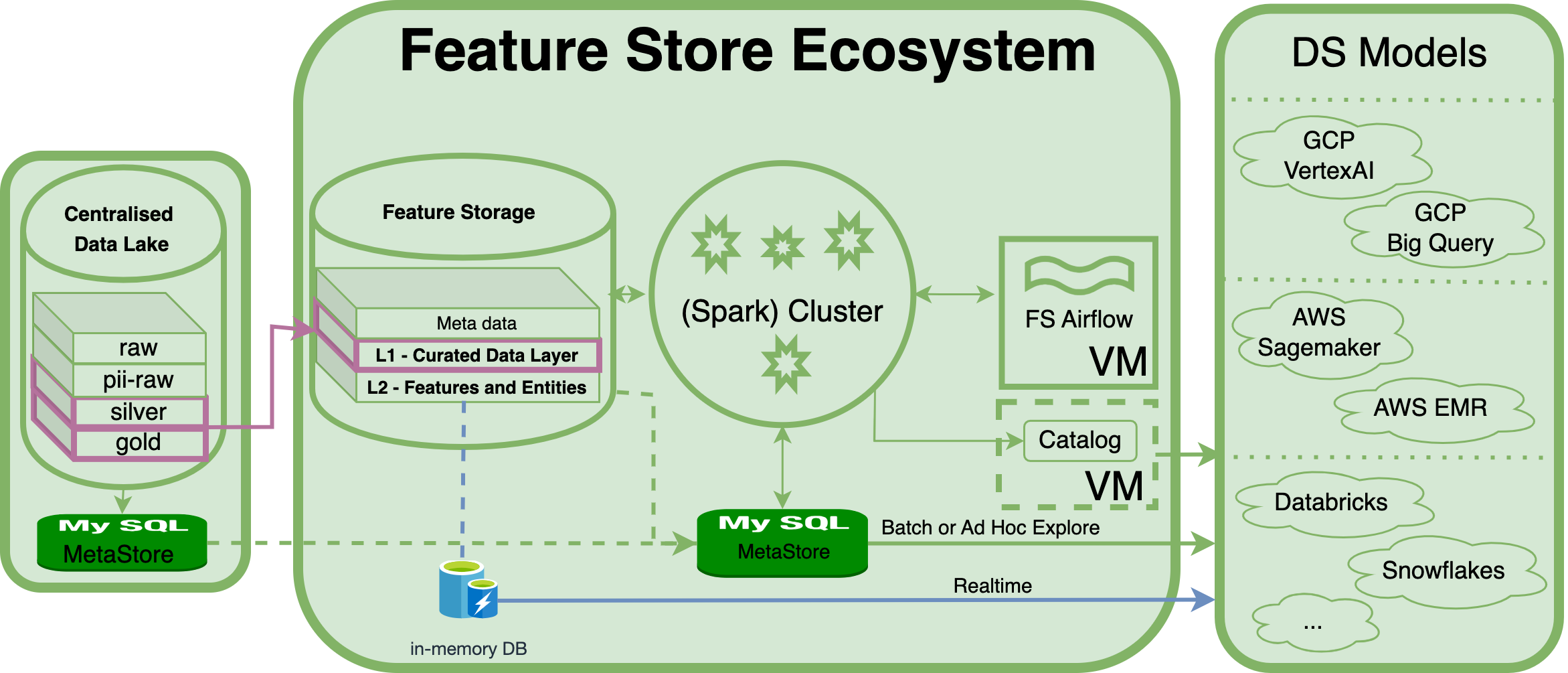
For companies embarking on digital transformation towards Data and AI, Data is the essential fuel while AI brings initial business value. Sufficient, high-quality data is crucial for AI projects. Good data quality, naming conventions, and a data catalog facilitate data scientist work.
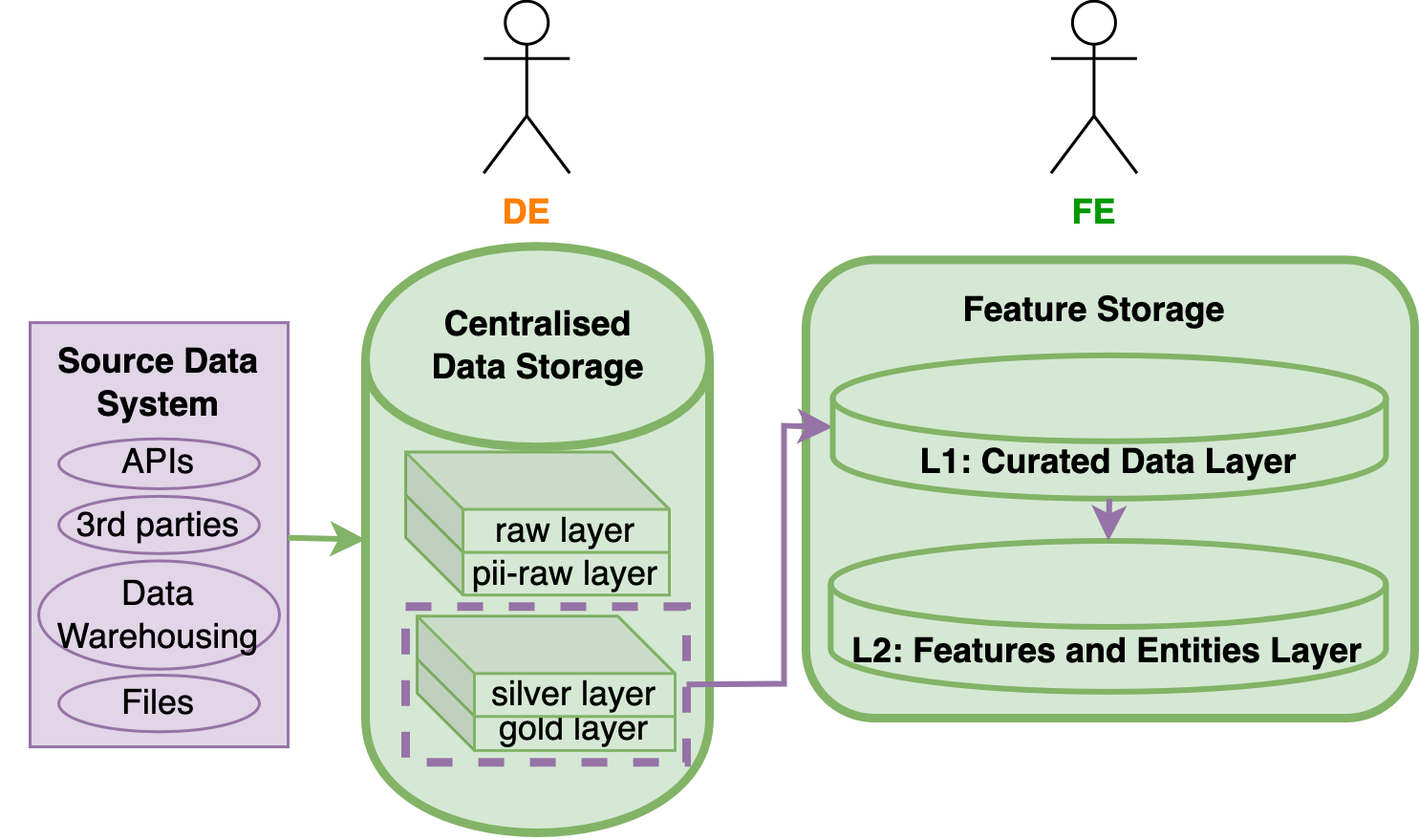
Centralized Data Lake or Centralized Data Storage
Data engineering typically establishes a centralized Data Lake serving enterprise needs like BI reporting and Data science. The Data Lake comprises layers:
- - Raw Layer: Onboards imperfect data as a buffer for Silver and Gold layers. Not used for business purposes.
- - PII Raw Layer: Separates and secures Personal Identifiable Information to comply with regulations.
- - Silver Layer: Trustable, minimal transformation, undergoes quality check and cleaning.
- - Gold Layer: In-depth transformation/ETL for specific data needs of BI and data usage teams.
Feature Preparation - L1: Curate Data Layer (CDL)
The Curated Data Layer (CDL) refines data into features and entities, ensuring feature store excellence. A CDL is vital for AI projects, even without a multi-layered Data Lake. It guarantees high-quality, structured data for accurate model training and analysis.
The 1st feature store layer generates all feature tables through ETL, customized Use Cases (UC), and real-time streaming.
Construct the CDL using solid data from the Silver and/or Gold layer of your centralized data lake. Without a data lake, this layer can build feature tables on raw files.
For distinctions between Gold and Curated Data layers, consult my Medium article (coming soon).
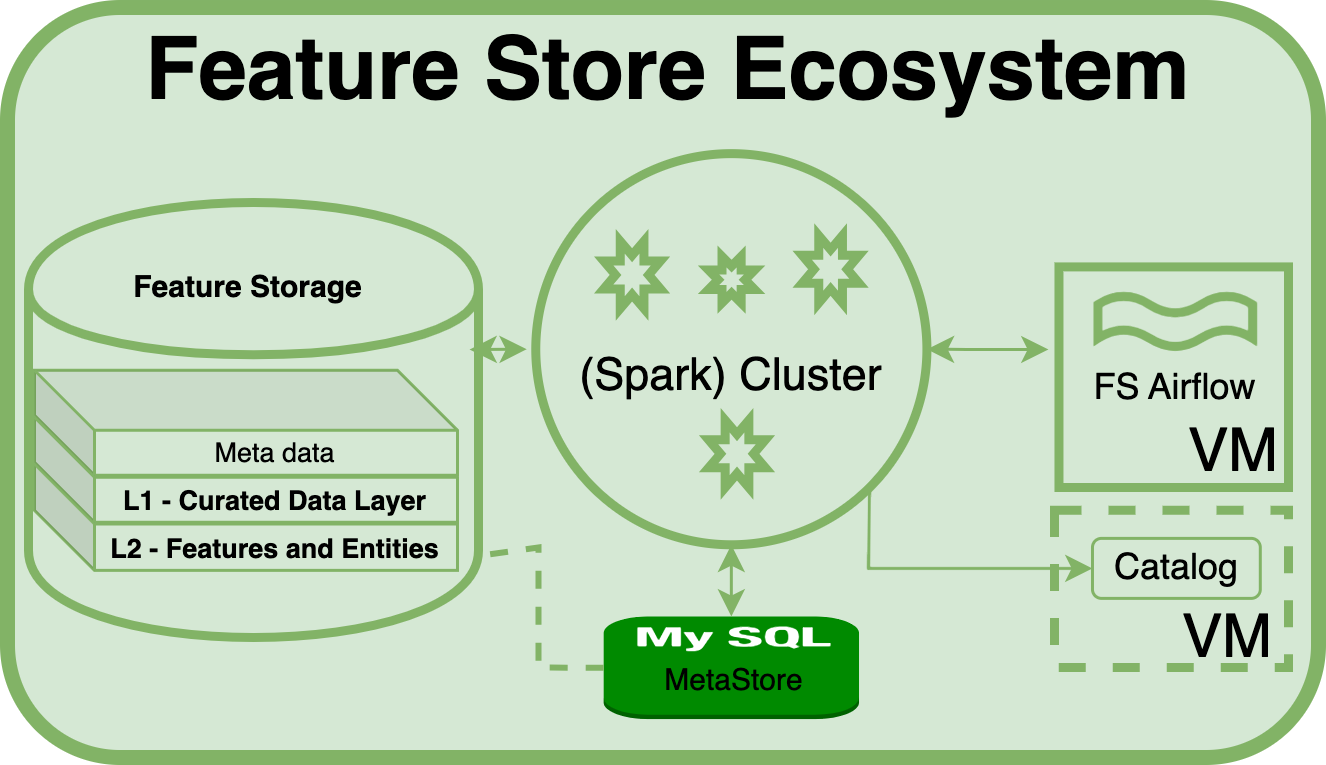
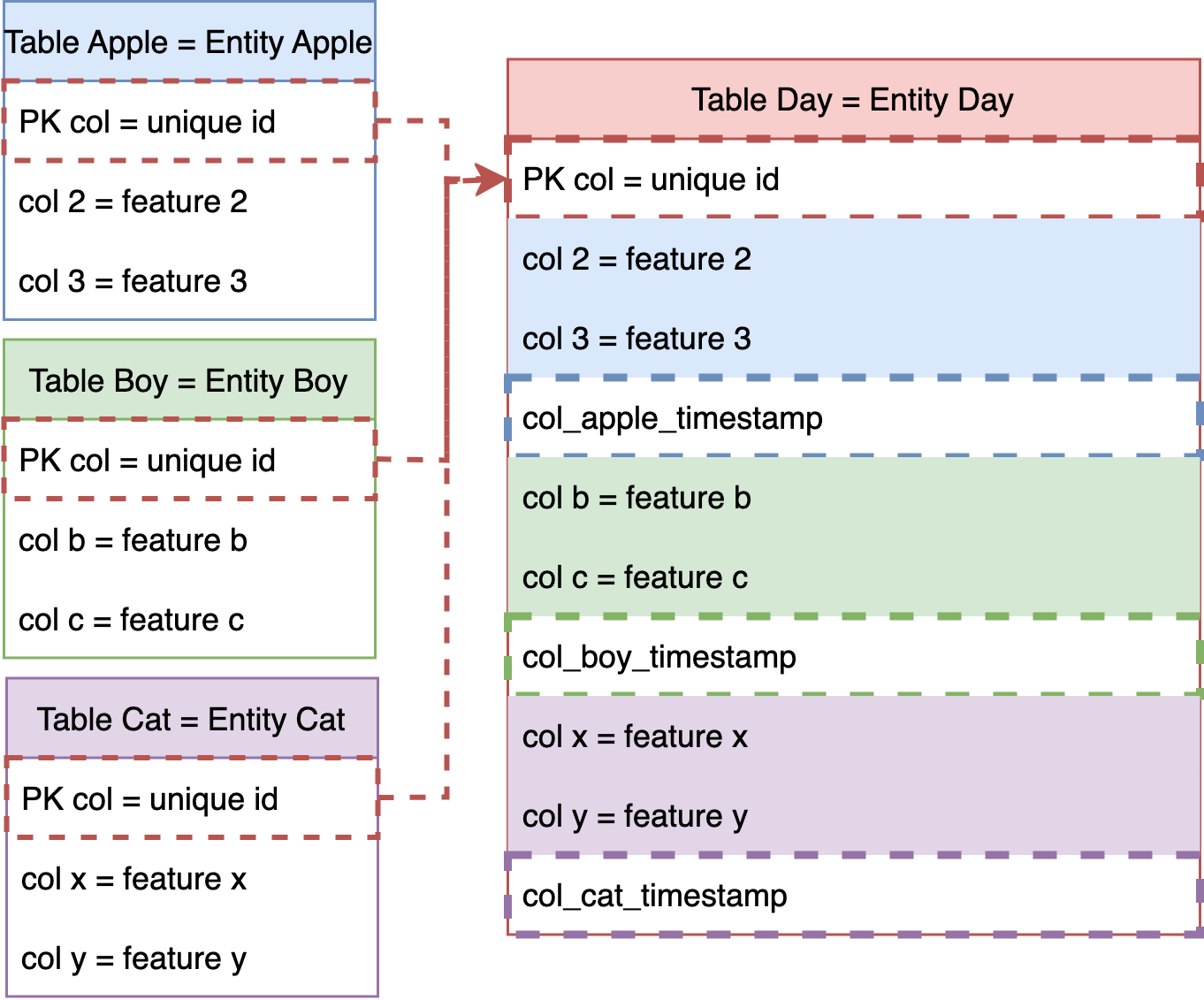
Feature Registration - L2: Features and Entities Layer
The second layer of the Feature Store is the Features and Entities layer. This layer generates and stores features derived from models. It also unifies features through MASTER COLUMNS, using Primary Key (PK) columns (e.g. Product ID), to integrate master feature columns into a FACT entity table. Timestamps are added to facilitate data science tasks such as training, prediction, and time-based analysis.
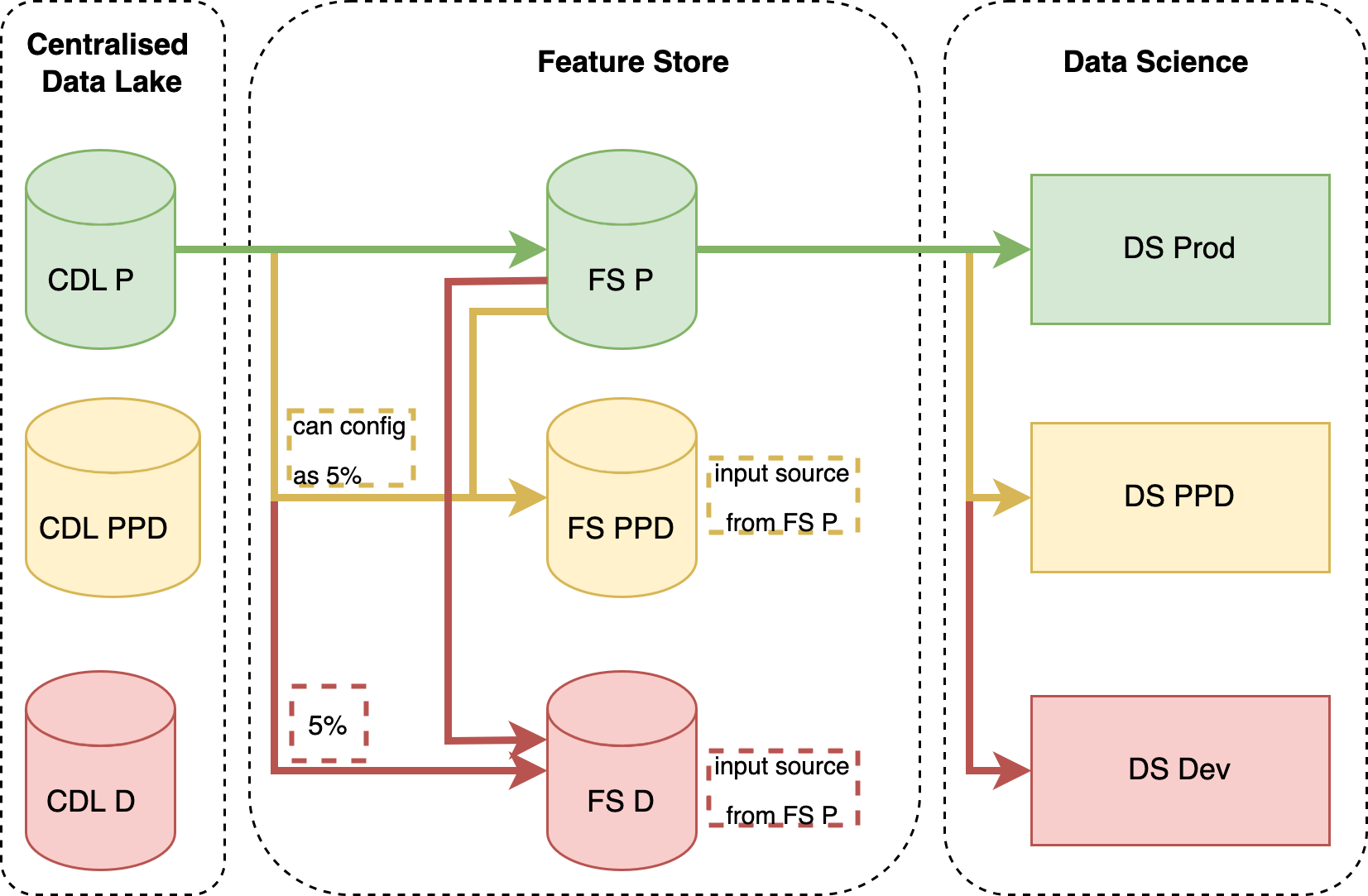
Feature Serving In Production
As software engineers, we recognize the need to replicate dev and pre-prod environments. However, in data and AI, independence among systems (data lake, feature store, data science) allows 'Prod-data-only' service. By smartly consuming data across ecosystems, over 50% of data copying costs are spared, and engineers save time on redundant data validation across environments.
Buy-to-Use Feature Stores (FS)
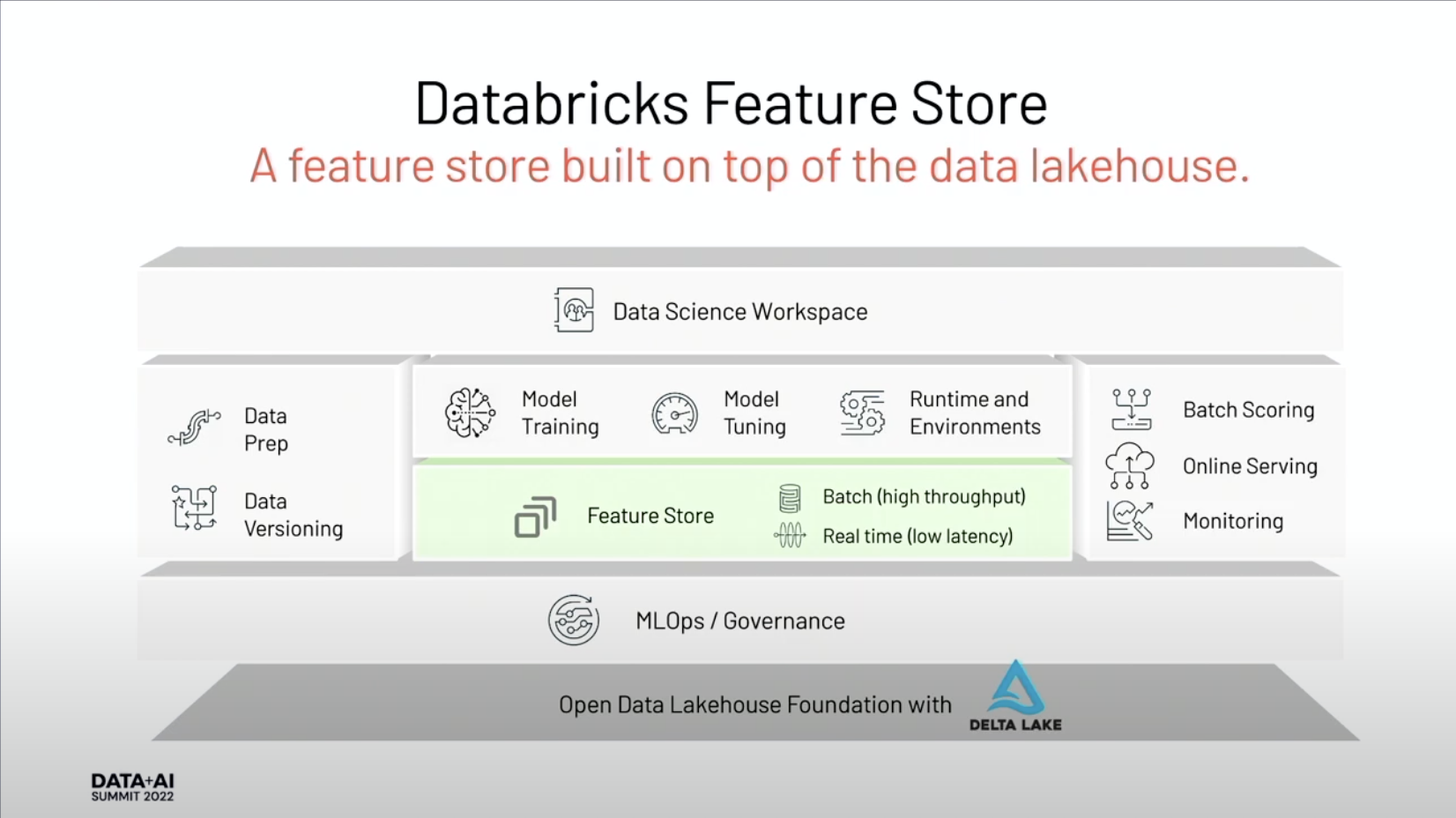
Databricks Feature Store
Databricks presents a managed platform with features monitoring. It caters to both batch and online features serving needs. Feature ingestion is managed through notebooks, making the process streamlined. The platform has strong integration with the Spark framework, enhancing its capabilities for data processing.
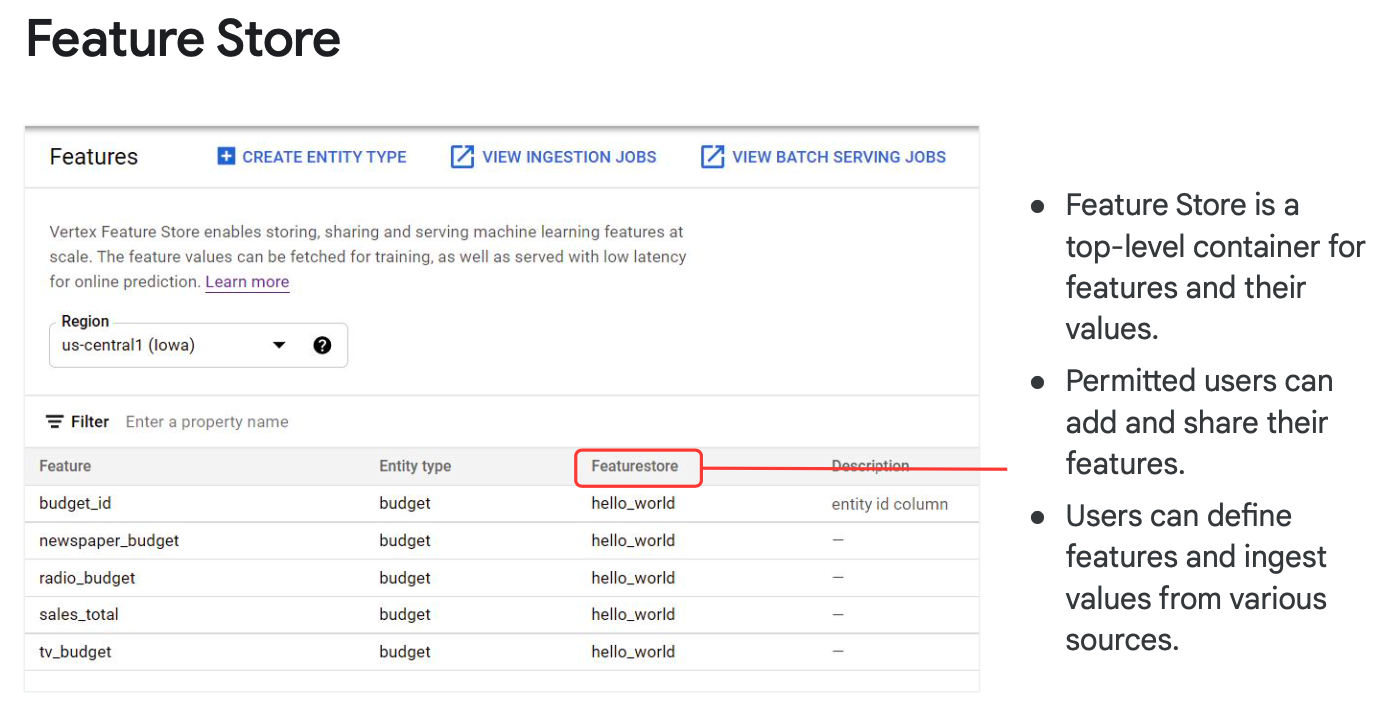
GCP Vertex AI Feature Store
The managed platform from GCP provides a robust solution. It currently supports BigQuery and GCS for feature sourcing. The platform offers built-in features monitoring and delivers highly scalable on-demand features serving. It facilitates entity joins and includes a web UI for easy management. However, it lacks post-processing features and point-in-time joins between entities.
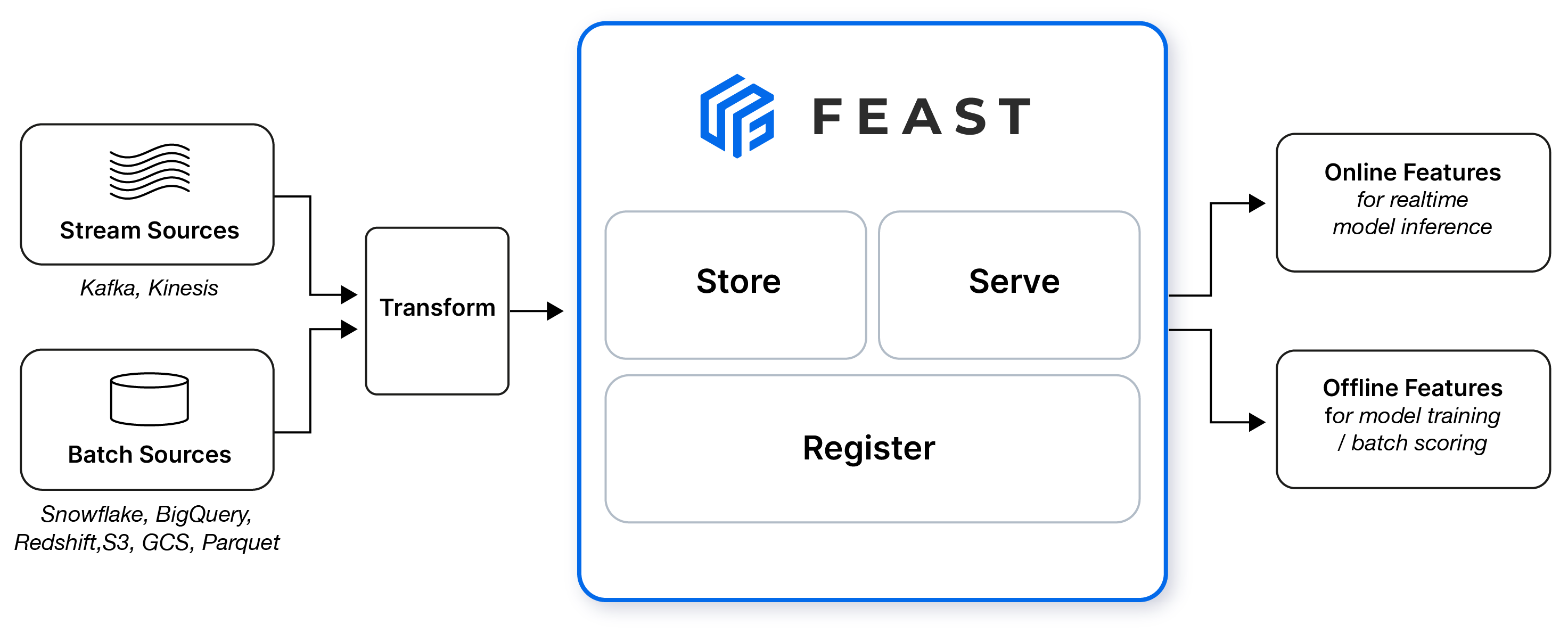
FEAST - Open Source Feature Store
FEAST, an Open Source tool, requires manual installation. Despite the absence of feature monitoring, it excels in point-in-time joins between entities. Setting up Kubernetes, a database, and a cache is necessary for scalable features serving. FEAST CLI enables local feature caching. While offering simple feature transformation, it's not designed as an ETL tool. It boasts connectors for a wide range of platforms and services, although its Web UI is experimental.
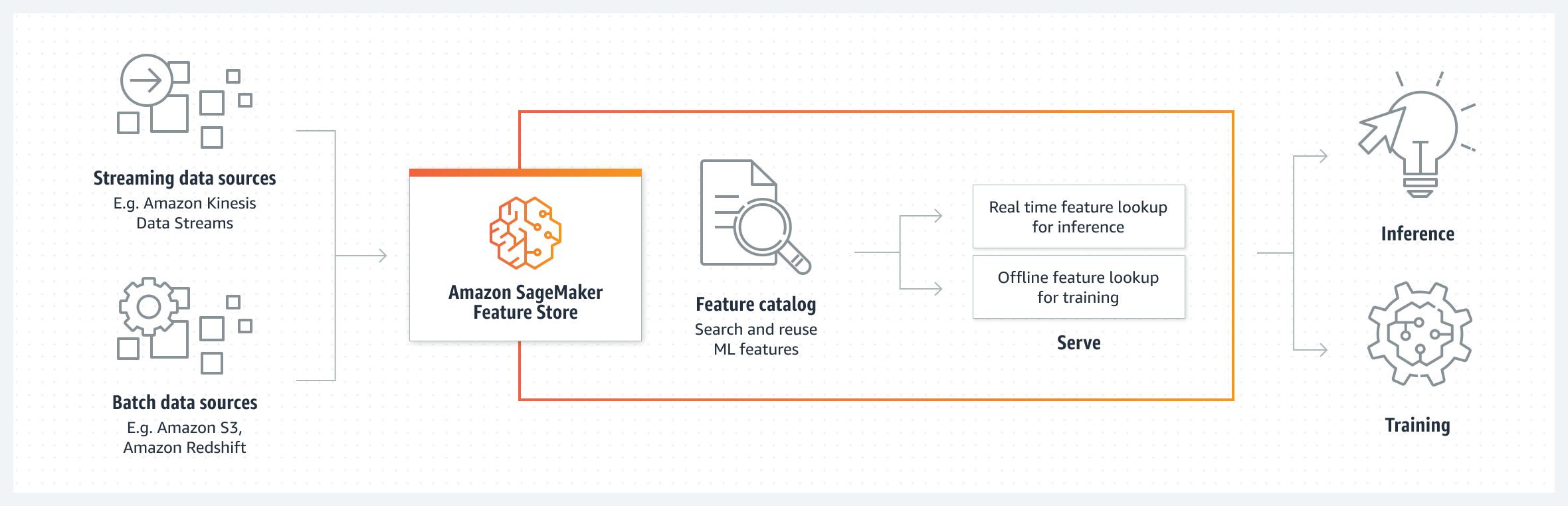
AWS Sagemaker Feature Store
AWS offers a managed platform designed for ease of use. It empowers users to store, discover, and share features across the SageMaker platform. Supporting data ingestions from batches and streams, it ensures offline and online access to features. The platform excels in both batch and online features serving scenarios.
How
A Software Development Kit (SDK) is a toolkit providing tools, resources, and pre-built components for efficient application development. SDKs save time, ensure consistency, offer access to features, reduce errors, and provide documentation, making them pivotal for streamlined software development.
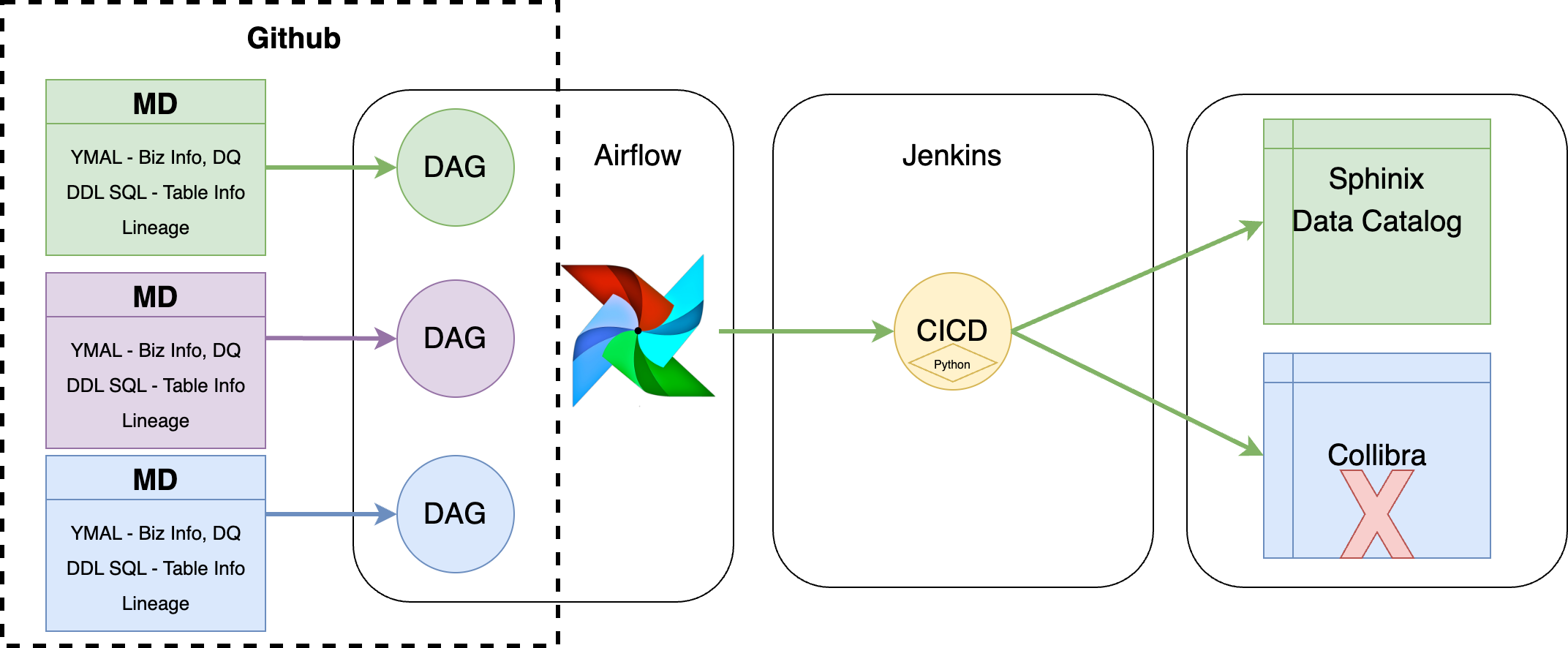
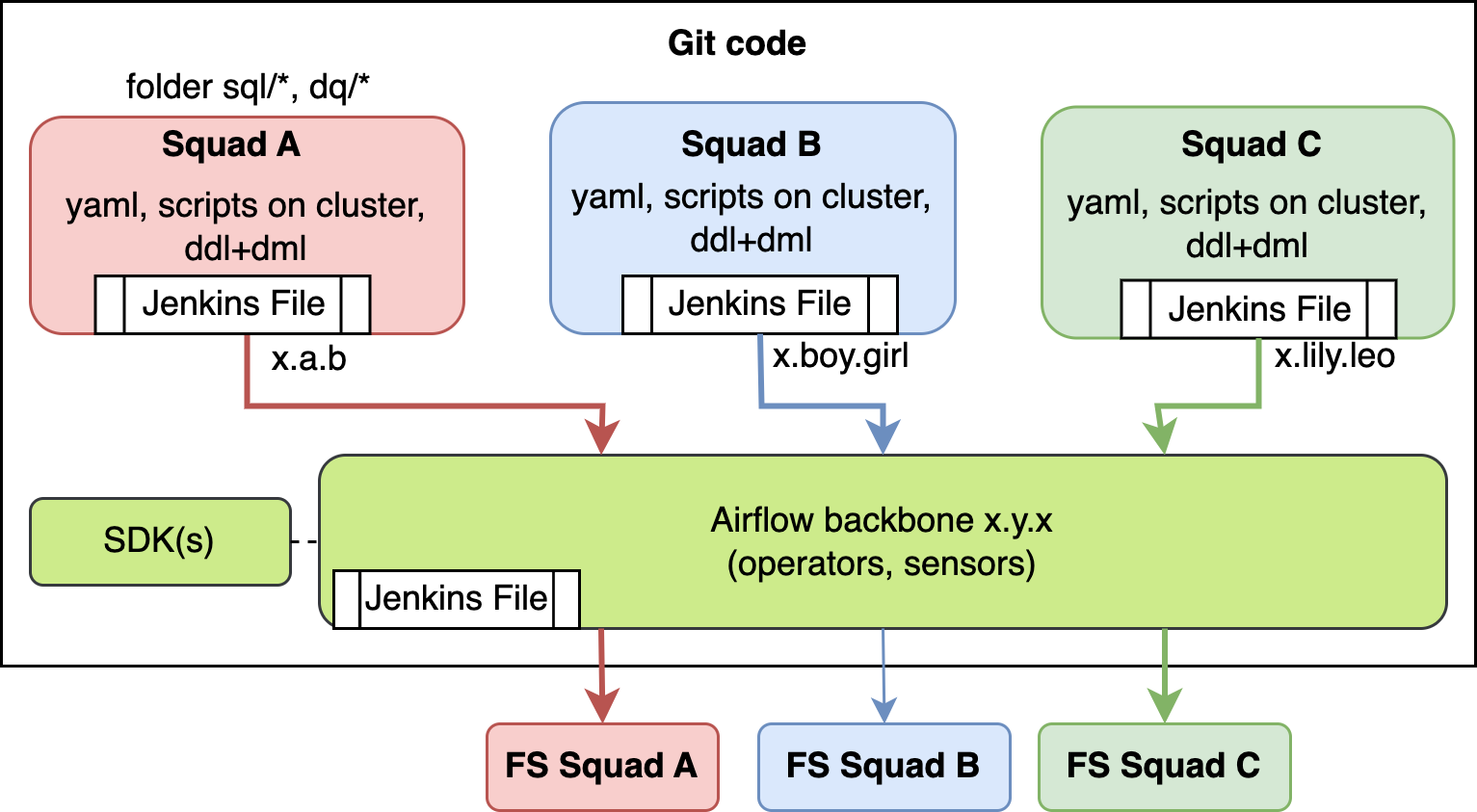
In building an enterprise-level feature store via open source, it's advisable to adopt a MESH concept (Data Mesh, ML Mesh) for multiple business Use Cases (UCs) or Squads. This approach avoids bottlenecks. Through the SDK method, each UC or Squad defines its specific needs and feature parameters. Utilizing smart CI/CD deployment, code is constructed and deployed to production environments, establishing an independent mesh for data science with no dependencies.
Process
Step 1, Establish a Strong Centralized Data Lake
The cornerstone of a successful feature store (FS) lies in a robust Centralized Data Lake foundation. Ensure data sources possess good quality, well-defined primary keys (PKs), and adhere to industrialized Naming Conventions.
Step 2, Define Features and Entities
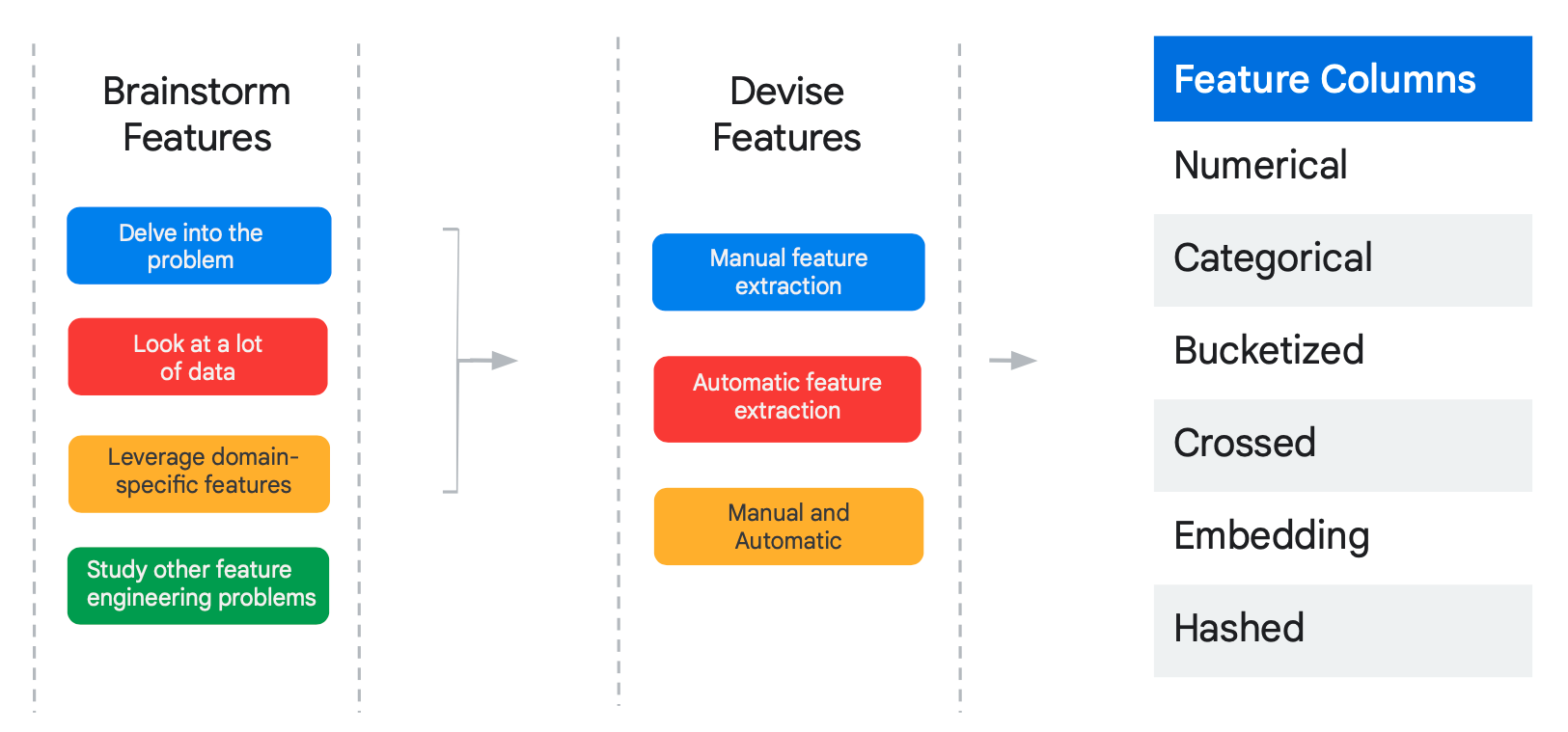
Feature Engineers (FEs) collaborate with Data Scientists (DS) and cross-functional squad members to precisely identify and outline entity and feature requirements for data science initiatives. Remember, a Feature Store should be agile, efficient, and potent. Precise definitions lead to superior features.
Step 3, Construction by Feature Engineers
Feature Engineers (FEs) craft features and entities within L1 and L2, releasing them to production with the Feature Store Catalog. This step ensures the availability of well-defined, high-quality features for use.